Wikipedie je jedním z nejvýznamnějších a nejrozsáhlejších zdrojů
informací na světě. Úložiště Wikimedia Commons,
sesterský projekt Wikipedie, plní obdobnou roli pro obrázky a další
mediální díla.
Pokud jste fotograf, zástupce firmy, producent nebo jste
držitelem autorských práv k autorskému dílu, můžete ho za pomocí
Generátoru svolení autora jednoduše věnovat
Wikipedii. Umožníte tak jeho celosvětové využití, které nebude
omezené jen na Česko.
Tato webová aplikace, dostupná na adrese svoleniautora.wikimedia.cz,
je jedním z nástrojů, kterými spolek Wikimedia Česká
republika usnadňuje rozvoj svobodných znalostí a přispívá
k růstu Wikipedie a dalších projektů.
Co je Generátor svolení autora?
Generátor svolení autora je užitečný nástroj, který umožňuje
darovat vizuální materiály Wikipedii a dalším projektům Wikimedia
bez nutnosti registrace. Tento nástroj mohou
využít nejen autoři daného díla, ale i držitelé autorských práv,
jako jsou dědici, galerie, producenti filmů nebo soukromé
společnosti.
Jak funguje Generátor svolení
autora?
Postup darování vizuálních materiálů je velmi jednoduchý a
přehledný:
Vyplnění formuláře: Zadáte své osobní údaje a
informace o materiálu, který chcete darovat. Zároveň uvedete, zda
jste autorem nebo držitelem autorských práv k danému materiálu.
Můžete specifikovat licenci, pod kterou má být materiál uvolněn, a
podmínky jeho použití.
Generování a odeslání e-mailu: Aplikace na
základě zadaných údajů vygeneruje e-mail. Ten pak zašlete na
uvedenou adresu. Odesláním e-mailu potvrzujete, že máte právo
materiál zveřejnit pod svobodnou licencí, která umožní jeho použití
na Wikipedii a dalších projektech Wikimedia
V případě jakýchkoliv dotazů se můžete mailem obrátit na
jan.beranek@wikimedia.cz nebo využít služeb Wikiporadny.
Kdo může Generátor svolení autora
využít?
Generátor svolení autora je otevřený široké škále uživatelů,
nejen individuálním autorům, ale také archivům, galeriím,
výtvarníkům, filmovým producentům a distributorům nebo neziskovým
organizacím různého typu a zaměření.
Zdědili jste archivní fotografie?
V případě, že jste dědicem autorských práv k fotografiím nebo
jiným vizuálním materiálům, máte právo s těmito díly nakládat
stejně jako původní autor. To zahrnuje i možnost darovat je
Wikipedii prostřednictvím Generátoru svolení autora. Jako dědic tak
můžete přispět k uchování a sdílení kulturního dědictví tím, že
umožníte, aby díla vašeho předka byla dostupná široké veřejnosti
prostřednictvím Wikipedie.
Jak je to s díly, které vytvořili vaši
zaměstnanci?
Autorský zákon upravuje tzv. zaměstnanecké dílo. Pokud je dílo vytvořeno v rámci
plnění pracovních úkolů, autorská práva k němu zpravidla náleží
zaměstnavateli, pokud není dohodnuto jinak. Tento fakt je důležitý
zejména pro organizace, které chtějí darovat fotografie nebo jiná
díla vytvořená jejich zaměstnanci. V takovém případě svolení musí
být uděleno osobou oprávněnou za organizaci jednat.
Ve dnech 29. a 30. září 2024 proběhlo pod hlavičkou Wikimedia
Europe pravidelné každoroční setkání pracovníků evropských poboček
Wikimedia, zabývajících se tématy advokacie a veřejných politik –
Big Fat Brussels Meeting. Toto setkání, které se konalo v
Bruselu, se letos věnovalo mimo jiné také prioritám nově zvoleného
Evropského parlamentu a Evropské komise. Na třicet účastníků se od
zástupců Wikimedia Europe dozvědělo, jaké legislativní iniciativy
lze od těchto orgánů ve stávajícím volebním období očekávat. Za
Českou republiku se setkání zúčastnil Vlastimil Slovák, koordinátor
advokačního programu Wikimedia ČR
Nové evropské orgány
V nově zvoleném parlamentu jsou již ustaveny všechny politické
frakce. Oproti minulému období lze pozorovat posun doprava, včetně
posílení krajní pravice. Staronovou předsedkyní Evropské komise se
stala Ursula von der Leyen. Ta byla pravděpodobně (hlasování je
tajné) zvolena většinou tvořenou tradiční proevropskou skupinou –
zástupci socialistů, zelených, liberálů a křesťanských demokratů.
Lze očekávat, že v budoucnu se v závislosti na projednávaných
agendách budou v Evropském parlamentu vytvářet alternativní
„tematické“ většiny, složené i se zástupců jiných frakcí. Na rozdíl
od Evropského parlamentu není složení Evropské komise zatím
definitivní. Nová komise bude v listopadu procházet tzv.
„grilováním“ v Evropském parlamentu. Teprve na jeho základě budou
její členové potvrzeni. Nebývá neobvyklé, že se po tomto
„grilování“ navrhované složení komise ještě změní. Ať již vše
dopadne jakkoliv, Evropská komise i Europarlament začnou s koncem
roku pracovat naplno.
Jaké legislativní iniciativy, důležité pro projekty Wikimedia,
lze v následujícím pětiletém funkčním období očekávat?
Implementace stávající legislativy
Na novou Evropskou komisi je vyvíjen politický tlak, aby
zpomalila nové legislativní projekty a soustředila se na zavádění a
prosazování pravidel přijatých v posledních letech. Jedním z
nejvýznamnějších legislativních aktů bylo Nařízení o
digitálních službách (Digital Services Act),
přijaté v roce 2022. Nařízení se soustředí především na zvyšování
bezpečnosti virtuálního prostoru s cílem regulovat nelegální obsah,
cílenou reklamu či šíření dezinformací. V souvislosti s ním je
připravována sekundární legislativa, upravující některé dílčí
otázky a metodické pokyny (guidelines) týkající se například
ochrany dětských uživatelů digitálních služeb. Právě Wikipedie je
dle tohoto nařízení kvalifikována jako tzv. velmi velká online
platforma a dopadá na ni tedy řada povinností. Její způsob
fungování se však diametrálně liší od ostatních subjektů
spadajících do stejné kategorie, kterými jsou třeba některé
sociální sítě. Nově přijímaná sekundární legislativa by tedy mohla
mít pro fungování Wikipedie nezamýšlené důsledky. I proto bude
hnutí Wikimedia vývoj sekundární legislativy a metodických
materiálů pečlivě sledovat a je připravena komunikovat naše
stanoviska zákonodárcům. Také Wikimedia ČR navázala kontakt
s některými českými europoslanci, kterým bude v případě potřeby
naše stanoviska napřímo tlumočit.
Dalším legislativním aktem, důležitým pro evropské pobočky
nadace, je tzv. Směrnice o ochraně osob zapojených do účasti
veřejnosti před zjevně neopodstatněnými žalobními návrhy nebo
zneužívajícími soudními řízeními. Tato směrnice s poněkud
krkolomným názvem (známa také jako tzv. Anti-SLAPP
Directive) byla přijata v dubnu 2024 a jejím cílem je mj.
chránit novináře či neziskové organizace před žalobami, které mají
za cíl těmto osobám zabránit ve vyjadřování a informování o
otázkách veřejného zájmu. Wikimedia Europe přiděluje této směrnici
mimořádnou důležitost, protože počet wikimediánů, kteří čelí
šikanózním žalobám, narůstá. Aktuálně čelí obdobným problémům
například kolegové z
estonské pobočky nadace Wikimedia. Implementační lhůta směrnice
končí v květnu 2026 a Wikimedia bude sledovat její kvalitu a průběh
v jednotlivých členských státech.
Nové legislativní návrhy
V nadcházejícím legislativním období lze očekávat přijímání nové
legislativy související s ochranou dětí na
internetu. Ačkoliv konkrétní návrhy zatím neexistují, je
možné, že součástí budou také požadavky na podmínění přístupu k
určitému typu obsahu kontrolou věku uživatele. Pro hnutí Wikimedia
se jedná o potenciálně problematický požadavek. Ačkoliv důležitost
ochrany dětí nelze zpochybnit, bude velmi záležet na konkrétní
podobě případných legislativních návrhů. Zavedení filtrování obsahu
na Wikipedii či na Wikimedia Commons podle věku může být velmi
složité. Sbírání dodatečných dat o uživatelích je navíc v rozporu
se zásadami, na kterých jsou projekty Wikimedia postaveny. V tuto
chvíli se zdá být zřejmé, že významná část zákonodárců považuje
zavedení kontroly věku alespoň na některých online platformách za
nutné. Strategií hnutí Wikimedia může být snaha o přesměrování
debaty od hlediska „kontroly věku online“ k více holisticky
pojatému hledisku „ochrany dětí online“, které nabízí širší škálu
prostředků, jejichž pomocí lze dosáhnout stejného cíle. Pokud
Wikimedia zvládne demonstrovat odpovědný a konstruktivní přístup,
naše šance být vyslyšeni ze strany zákonodárců se zvýší.
V prosinci roku 2026 dojde k revizi Směrnice o
audiovizuálních mediálních službách. V průběhu revize bude
posouzeno její stávající fungování a velmi pravděpodobně dojde k
úpravám. Stávající znění stanoví pravidla fungování audiovizuálních
médií, a to jak tradičního televizního vysílání, tak různých
internetových audiovizuálních platforem. Předmětem politické debaty
je zejména systém kvót, který stanoví, že 30 % audiovizuálního
obsahu nabízeného některými typy poskytovatelů online musí mít
původ v zemích EU. Wikimedia se v této souvislosti chce ujistit, že
při úpravě směrnice nebude žádný z našich projektů nedopatřením
zahrnut pod tato omezení.
V oblasti audiovizuálních služeb lze také očekávat
(pravděpodobně v průběhu roku 2025) debatu o stávající podobě
regulace geoblockingu, tedy omezení přístupu k
internetovému obsahu na základě geografické polohy uživatele. V
této souvislosti se bude hnutí Wikimedia zasazovat o to, aby byl
zohledněn veřejný zájem na přístupu k informacím a vzdělávacímu
obsahu, včetně otázek spojených s geografickou blokací
veřejnoprávního vysílání.
Pouhé měsíce nazpět byl schválen zásadní předpis regulující
používání umělé inteligence, AI Act. Není
tedy pravděpodobné, že by v následujícím období byly v této oblasti
navrhovány nové předpisy. Vyloučit to nicméně nelze, protože
vykonavatelé autorských práv (kolektivní správci, vydavatelé,
hudební producenti a nakladatelství) začínají čím dále tím
hlasitěji upozorňovat na fakt, že umělá inteligence je školena na
autorsky chráněném obsahu, aniž by byla reflektována práva autorů.
Je tedy možné, že Evropská komise či Evropská rada budou na jejich
hlas v budoucnu reagovat.
Jak je zřejmé, v oblasti evropské politiky se děje řada
zajímavých věcí, které mohou mnohdy i zásadním způsobem ovlivnit
fungování projektů Wikimedia. Virtuální prostor se mění obrovskou
rychlostí a regulace se na tyto změny snaží reagovat. Nikdo z nás
nemůže s jistotou říci, jak bude online svět vypadat na konci
pětiletého funkčního období nových evropských orgánů. Je tedy
možné, že se objeví legislativní návrhy, o jejichž povaze v tuto
chvíli nemáme ponětí. Wikimedia Česká republika spolu s celým
hnutím situaci sleduje. Budeme vždy usilovat o to, aby naše
projekty zůstaly svobodné, neutrální, otevřené a přístupné co
nejvyššímu počtu lidských bytostí.
Wiki-rezidentství je forma spolupráce, kdy se
zaměstnanci institucí stávají wikipedisty a pomáhají institucím,
jako jsou muzea, archivy či knihovny, s tvorbou a rozšiřováním
obsahu na Wikipedii. Wiki-rezidenti a wiki-rezidentky koordinují
nahrávání fotografií, vytváření článků a propojují data s Wikidaty.
Spolupráce často zahrnuje i školení zaměstnanců a veřejnosti v
editování. Příkladem jsou projekty v Muzeu Východních Čech nebo
Státním oblastním archivu v Praze, kde rezidenti zpřístupnili
stovky fotografií a rozšířili články o významných osobnostech a
tématech. Tato práce přispívá ke svobodnému sdílení informací a
kulturního dědictví. Jak se dařilo „našim“ wiki-rezidentům a
wiki-rezidentkám v uplynulé sezoně?
Zkušenosti a know-how
Wiki-rezidentství je pomyslným vrcholem naší spolupráce v
(globálním) projektu GLAM (galerie, knihovny, muzea). Jde o
vytvoření pozice wiki-přispěvatele či přispěvatelky v dané
instituci – ať už zapojením zkušeného editora či editorky či
proškolením některého ze zaměstnanců a zaměstnankyň instituce v
přispívání do Wikipedie a jejích partnerských projektů. Jedním z
nich je hlavní wiki-rezident
Lukáš Nekolný, nebo „létající“ wiki-rezident Jaroslav
Zastoupil (alias Gampe).
Wiki-rezident je osoba, která v dané instituci
pracuje na zlepšování obsahu Wikipedie a dalších Wikimedia
projektů. Jejím úkolem je obvykle koordinovat nahrávání
relevantních materiálů, vytváření nebo vylepšování článků
souvisejících s danou institucí a jejími sbírkami, a také
podporovat vzdělávání a zapojování dalších zaměstnanců nebo
veřejnosti do editování Wikipedie.
Jaroslav Zastoupil se věnuje vlastní wiki-rezidentské spolupráci se
Státním oblastním archivem v Praze, kde má na starost nejen
rozšíření článků, ale také zpřístupnění raritních fotografií z
továrny Koh-i-noor
Waldes nebo paní Sidonie
Nádherné.
Pražská tramvaj ve službách
reklamy firmy Waldes a spol. před vozovnou u bývalé Orionky, 1913.
Koh-i-noor, a. s., spisovna, nezpracováno. Autor: Anonymní – Státní
oblastní archiv v Praze, Volné dílo, via Wikimedia
Commons.
Lukáš Nekolný zase svou wiki-rezidentskou práci vykonává v Muzeu
Východních Čech, kde má na starosti nejen koordinaci,
zpřístupňování sbírek, ale také systematickou práci na článcích a
tématech s muzeem souvisejících. Co to přesně znamená? Muzeu
Východních Čech v Hradci Králové se podařilo
aktualizovat přehled sbírek, nahrát přes
300 fotografií, ale také rozšířit počet článků souvisejících s
muzeem ze 2 na 11 (s celkovou návštěvností přes 10 500 za rok
2023). Více informací popisuje Lukáš ve svém
blogovém příspěvku.
Nově zrekonstruovaná
Gayerova kasárna. Autor: Archiv Muzea východních Čech v Hradci
Králové – Muzeum východních Čech v Hradci Králové, CC BY-SA 4.0,
via
Wikimedia Commons.
Od tradičních partnerů k nováčkům
Wiki-rezidentská spolupráce není nikdy čistě formálním aktem,
přestože jsou některé spolupráce v Programech pro partnerství
podloženy memorandem. Cílem spolupráce je maximální zpřístupnění
sbírek, informací a kolekcí veřejnosti. A to v jakékoliv podobě.
Dlouhodobá a viceúrovňová spolupráce probíhá například s
Univerzitou Karlovou v Praze, Státním oblastním archivem v Praze
nebo s Národní knihovnou.
Druhá zmíněná instituce má vzhledem ke svému záběru
wiki-rezidentů hned 7 (a celkem 11 zapojených zaměstnanců). Jejich
činnost koordinuje knihovnice Linda Jansová. Rozpětí jejich práce
zahrnuje aktualizaci stránek, nahrávání archiválií a fotek z akcí
knihovny, ale i propojování bibliografických i jiných databází s
wikidaty (podrobněji jsme o wikidatové spolupráci psali
v samostatném článku). Rozsáhlé kolekce metadat jsou pro
projekty Wikimedia stěžejní, proto je věnována této spolupráci
významná pozornost.
Výsledkem této dlouhodobé kooperace byl také webinář Obrázky z internetu a
autorské právo, který měl pomoci knihovníkům zorientovat se ve
složité problematice autorských práv a svobodných licencí. Více než
2 200 zhlédnutí videa a přes padesát otázek, které byly zodpovězeny
na stránce autorskepravo.wikimedia.cz,
svědčí o velkém zájmu o toto téma nejen mezi knihovníky.
Mezi staronové spolupracující instituce (nově s pozicí
wiki-rezidenta) patří Institut umění / Divadelní ústav, který již
dříve spolupracoval zejména na wikidatové bázi. V současnosti se
tato spolupráce opět otevřela a s ní i zapojení tří divadel –
Divadla na Vinohradech (wiki-rezident Jiří Brožek je zároveň
vedoucím archivu divadla), Dejvického divadla (kde působí
wikipedista Gampe) a HaDivadla v Brně. Na Wikimedia Commons
naleznete už nyní zveřejněné fotografie fotografa Petra Chodury z
Divadla na Vinohradech..
Představení Lakomec. Divadlo
na Vinohradech. Autor: Petr Chodura – vlastní dílo, CC BY-SA 4.0,
via Wikimedia
Commons.
Brněnské HaDivadlo v rámci
oslav 50. výročí divadla bilancuje a připravuje na Wikipedii
kvalitní prezentaci divadla včetně historických fotografií.
Wiki-rezidentem je zde mladý absolvent a redaktor Milan Hábl, který
koordinuje celý edukační tým divadla. Cílem je zpřístupnění
fotografií a zpracování chybějících hesel osobností HaDivadla pro
českou Wikipedii.
Wiki-rezidentstvím to nekončí
Průběžná spolupráce proškoleného wiki-rezidenta či
wiki-rezidentky je základem úspěšných společných GLAM výstupů. Mezi
takové se řadí například Jana
Škodová, která po Lukášovi Nekolném převzala v roce 2023 (a
několika letech absence rezidenta) pozici wiki-rezidentky v
ZOO Praha.
Pravidelné editace a zpřístupňování obrázků chybějících obyvatel
pražské ZOO svědčí o tom, že si tato instituce uvědomuje edukativní
význam jejího působení i na české Wikipedii.
Wiki-rezident je ve výsledku prostředkem k naplnění vize
svobodné kultury a svobodného přístupu k informacím a uměleckým či
vědeckým dílům pro kohokoliv bez omezení. Na prvním místě je zájem
dané organizace či instituce sdílet. Příprava konkrétního
wiki-rezidenta je pak procesem, se kterým Wikimedia ČR významně
pomáhá.
Stávající práce a úsilí wiki-rezidentů a wiki-rezidentek ve
spolupracujících institucích naráží na některá úskalí. Jedním z
nich je čas, který mohou této práci věnovat. Výhodou je, pokud je
wiki-rezident či wiki-rezidentka zaměstnancem instituce a může část
svého úvazku věnovat zpřístupňování a osvětě (mnohdy jako
zaměstnanec edukačního oddělení). Externí spolupráce naráží zase na
přístup k informacím, sbírkám a provozní nesnáze. Nicméně
organizace, které toto byly schopny vyřešit, výrazně navýšily svou
kapacitu sdílet a zpřístupňovat svůj obsah veřejnosti.
Tam, kde je zájem o spolupráci a ochota dedikovat část kapacit
na proškolení wiki-rezidentů a zpřístupnění sbírek, velmi rádi
spolupráci navážeme. Můžeme připravit speciální školení na
Wikipedii, nahrávání na Wikimedia Commons nebo Wikidata. Můžeme
zorganizovat editaton, přednášku či školení ve vybrané instituci
(jako je tomu již roky s Národní knihovnou). Případně můžeme
zareagovat na individuální poptávku a spolupráci postavit na
klíč.
Všech našich partnerů i wiki-rezidentů si nesmírně vážíme a jsme
moc rádi, že s nimi můžeme spolupracovat na šíření svobodné kultury
a sdílení informací. Děkujeme vám!Více informací o podmínkách
spolupráce naleznete na
této stránce, případně na
projektových stránkách jednotlivých zapojených institucí.
Wiki-rezidenti na setkání 5.
března 2024 v Akademii věd. Autor: Richard Sekerak (WMCZ) – Vlastní
dílo, CC BY 4.0, via Wikimedia
Commons.
Rok 2023 byl pro nás obdobím růstu a úspěchů, zejména v oblasti
programů, spolupráce s partnery a zapojení široké české komunity.
Dosáhli jsme rekordního počtu aktivit a nových partnerství, což nám
umožnilo rozšířit naši činnost a posílit a zpestřit zapojení
dobrovolníků i institucí. Vytvoření strategického plánu pro roky
2025–2027 staví na těchto základech a zaměřuje se na dopad a
provázanost ve spolupráci s komunitou i partnery, přičemž
reflektuje naše mezinárodní vazby a trendy v hnutí Wikimedia.
Těšíme se na další rozvoj v dalších letech, kdy budeme nadále
posilovat otevřenost, rovnost příležitostí a efektivitu našich
aktivit.
Naše strategie pro budoucnost
V letošním roce jsme vytvořili v pořadí třetí strategický plán.
Ten první, pro roky 2017–2020, byl vytvořen několika aktivními
členy ve fázi, kdy spolek po desetiletém dobrovolnickém fungování
najímal první zaměstnance. Plán se v cílech vztahoval k budoucí
profesionalizaci spolku a odrážel přání tehdejších členů o jeho
směřování.
Druhý strategický plán pro roky 2021–2024 již reflektoval
postupující profesionalizaci spolku a byl tvořen členy spolku
dohromady se zaměstnanci. Bohužel jsme se však při jeho tvorbě
potýkali s některými nesnázemi. Tehdy se nám nepodařilo ideálně
zapojit všechny hlasy z komunity. Naštěstí jsme si, věřím, z toho
vzali ponaučení a výrazně jsme se zaměřili na budování vztahů
napříč českou komunitou. Naše otevřenost a kapacita v tomto ohledu
postupně vzrostla.
Strategický plán pro roky 2025–2027 jsme
připravovali od listopadu 23’ do letošního května. Při jeho tvorbě
jsme se už mohli opřít o již popsanou strukturu české komunity.
Využili jsme při tom poznatky z interního výzkumu,
který nám poskytl cenné vhledy do rozložení komunity a jejích
potřeb. Zaměřili jsme se na to, jak oslovit všech jejích 15
podskupin a jak je zapojit do přípravy. Pro část tvorby jsme
využili externí facilitaci. Propojení různých pohledů ladí s
mezinárodními procesy v hnutí Wikimedia. To samé platí o zkrácení
plánu na tři roky. I díky tomu můžeme lépe plánovat a efektivněji
reagovat na zpětnou vazbu.
Ohlédnutí za rokem 2023
Emajeblahova, CC0, via
Wikimedia Commons
Pro správné plánování budoucnosti spolku je nezbytné umět
zanalyzovat současnost a bilancovat minulost. Pojďme se proto
společně podívat za rokem 2023 – tedy na situaci, na níž nový
strategický plán bezprostředně navazuje. I to nám umožňuje
vyhodnocovat dopad našich aktivit a strategicky je plánovat.
Detailní popis všech akcí a činností ve vzdělávacích
programech, programech pro komunitu a partnerství najdete
vevýroční zprávě za rok 2023.
Jsem vděčná všem, kteří nám v roce 2023 pomohli zrealizovat tak
velké množství kvalitních akcí. Uspořádali jsme nebo podpořili
celkem 330 aktivit, což je historicky nejvyšší
počet, a zapojili jsme téměř 4 000 účastníků.
Velmi mě těší zejména to, že mezi nimi bylo více než 1 500
žen a téměř 1 800 nováčků. Dokazuje to,
že se nám daří otevírat dveře novým tvářím a posilovat rovnost
příležitostí. Naši komunitu editorek a editorů jsme rozšířili o
697 nově registrovaných uživatelů a uživatelek,
čímž naplňujeme naši roli v budování české wiki-komunity.
Nesmíme opomenout ani naše partnery – s nimi jsme měli
239spoluprací, 51 z nich s námi
spolupracovalo poprvé. Do akcí se zapojilo 213organizátorů a organizátorek z řad naší komunity.
Spolupráce programu GLAM s institucemi (galerie, knihovny, muzea),
školami a neziskovými organizacemi nám pomohla naplňovat naši vizi
a rozšiřovat naši působnost napříč republikou. Společně
jsme editovali více než 4 100 článků, z nichž přes 1 500
bylo nových. Navíc jsme nahráli téměř 12 000 souborů na
Wikimedia Commons a vytvořili či propojili přes
408 000 položek na Wikidatech.
Mezi našimi klíčovými činnostmi bylo i 12 spolkových akcí,
kterých se zúčastnilo 243 lidí, včetně 98 žen a 29 komunitních
organizátorů. Jednou z mezinárodních aktivit bylo listopadové wiki-setkání mládežestřední a východní Evropy, které jsme
zorganizovali v Praze za podpory Wikimedia CEE Hubu. Vidět, jak se
mladí lidé z různých zemí propojují, nás naplňuje velkou
radostí.
Kvartální výzvy: Ženy, lidská práva,
Československo a Czech Wiki Photo
Strategicky jsme se zaměřili na tři klíčová témata: ženy, široké
téma lidských práv a Československo. Díky projektům jako Měsíc žen na Wikipedii můžeme cíleně pracovat
na větším zapojení žen-editorek a větším množství ženských
biografií. Lidská práva na Wikipedii nám zase otevřela
prostor pro spolupráci s experty a institucemi, které se těmito
tématy zabývají, a výzva Československo nám umožnila oslovit studenty a
studentky a navázat nové spolupráce s institucemi jako je
Vojenský historický ústav. Naše čtvrtletní tematické výzvy
doplňuje foto-soutěž Czech Wiki Photo. Všechny tyto výzvy a soutěže
propojují různé programy a aktivity, což je obrovský přínos pro
naše dlouhodobé plánování.
Rozvoj partnerství i komunity
Jedním z milníků minulého roku bylo podepsání memorand o
spolupráci s
Univerzitou Karlovou a
Národní knihovnou ČR , které podpoří náš další strategický
rozvoj. V obou případech jsme navázali na dlouholetou spolupráci.
Fakt, že se naše cíle v mnohém překrývají, povede k navyšování
efektivity společné práce. S partnery se každoročně setkáváme u
příležitosti
Večera svobodné kultury, kde nejen vyhlašujeme vítěze Czech
Wiki Photo, ale také s partnery pořádáme veřejnou besedu na téma
svobodné kultury – naposledy pod názvem Jak sdílíme? aneb
Svobodná kultura v praxi veřejných kulturních a paměťových
institucí.
Výstupy z výzkumu komunity, který vedla Jana
Landsingerová za podpory Jana Spousty, nám poskytly cenné vhledy do
struktury komunity a jejích potřeb. Díky tomu můžeme lépe plánovat
a efektivněji reagovat na zpětnou vazbu.
Jedním z dalších klíčových projektů bylo měření dopadu našich
činností. Ve spolupráci se studentem ČVUT Ivo Kořínkem jsme začali
vyvíjet nástroj Wikinside, který nám už teď výrazně usnadňuje
průběžné měření a reportování výsledků našich výzev. Tento projekt,
podpořený nadací OSF, nám otevírá dveře k efektivnějšímu
fungování.
Výrazný nárůst zaznamenala oblast komunitních minigrantů, jíž jsme se v roce
2023 strategicky věnovali. Vytváříme tak větší prostor pro
realizaci aktivit dle komunitních a lokálních potřeb.
Další cestou, jak budovat vztahy v komunitě, je podpora komunitní Wikikonference. Členky a členové
spolku se tak navíc přímo podílejí na naší programové činnosti a
realizují myšlenky, které považují pro rozvoj naší organizace za
důležité.
Rok 2023 byl také rokem posilování naší pozice v mezinárodním
hnutí Wikimedia. Podíleli jsme se na realizaci mezinárodní
strategie hnutí do roku 2030 a aktivně jsme budovali regionální
spolupráci, zejména jako členové Wikimedia
CEE Hubu. Měla jsem tu čest být podruhé vybrána do
jeho řídícího výboru, což vnímám jako velké ocenění naší práce.
Iniciovali jsme také vznik
CEE Youth skupiny, která propojuje mladé wikimediány z
celé střední a východní Evropy. I nadále v našem hnutí vnímám
výrazný potenciál pro rozvoj mladých lídrů a lídryň.
Velmi mě také těší, že jsme poprvé spoluorganizovali výroční
setkání Wikimedia
Europe v Praze, kde jsme byli jednou ze zakládajících
organizací. Tyto příležitosti nás posilují a dávají nám možnost
podílet se na budování otevřeného a kooperativního prostoru nejen v
České republice, ale i globálně.
Těším se, co nám přinese zbytek roku 2024, věřím, že jsme na
správné cestě a že i nadále budeme spolupracovat a dosahovat
skvělých výsledků. A to i díky vám všem, kteří naši činnost jakkoli
podporujete nebo se na ní přímo podílíte.
Na světovém úložišti Wikimedia
Commons je v současné době přes 10 milionů
fotografií a mnoho z nich není využito v žádném článku na
Wikipedii. To chce změnit výzvaWikipedia Pages Wanting Photos, která se která
se zaměřuje na doplňování (už nahraných) obrázků do článků bez
vhodných ilustrací.
Proč Wikipedie potřebuje
obrázky?
Článek bez obrázku je jakojídlo bez
koření. Bez vizuálního prvku ztrácí text na atraktivitě a
schopnosti zaujmout čtenáře, podobně jako jídlo bez chuti postrádá
požitek. Vizuální obsah obohacuje sdělení a pomáhá lépe ilustrovat
myšlenky, což je klíčové pro efektivní komunikaci informací.
Foto: Fort charles 1920, CC
0 via Wikimedia Commons
Porovnání prvních dvou
ročníků
V roce 2023 spolekWikimedia Česká
republikavůbec poprvé uspořádal české kolo
této výzvy. Do loňského kola se zapojilo celkem 6
účastníků a bylo doplněno 41 fotografií do článků. Na základě zájmu
komunity jsme se rozhodli letos uspořádat druhý ročník národní
výzvy. V letošním roce se do soutěže zapojilo 27 účastníků,
kteří doplnili obrázky do 592 článků.
Výsledky WPWP Czechia 2024
Na prvním místě se umístil Milda90 s
135 editacemi. Na druhém místě se umístil
Aktron s rozdílem pouhé jedné editace. Na třetím
místě se umístil Kolomazník s 80
editacemi.
Foto: Mončičák od
společnosti Ajena z 80. let 20. století , by: Rundvald,
CC-BY-SA 4.0 via Wikimedia Commons.
Minulý měsíc se v polských Katovicích sešlo na 1100 lidí a
dalších 1500 se připojilo online, aby společně oslavili hnutí
Wikimedia a zapojili se do diskuzí o jeho budoucnosti a směřování.
Zastoupeno zde bylo 143 zemí světa, a ani my, Wikimedia Česká
republika, jsme na konferenci Wikimánie nemohli chybět. Část
zaměstnanců se také podpořila přípravy programu či akce
samotné.
Wikimánie
je každoroční konference, oslavující všechny projekty svobodného
poznání pod záštitou Nadace Wikimedia. Jde o tři dny plné
konferencí, diskuzí, setkání, školení a workshopů. Letošní ročník
probíhal od 7. do 10. srpna a celkem bylo pro účastníky k dispozici
více než 300 sekcí (ve 12 okruzích v 8 paralelních místnostech).
Kromě toho se konaly další doprovodné akce, jako byl
WikiWomen Summit, Wikimanie
2024 Hackathon a mnoho dalších.
Sdílíme zkušenosti a dobrou praxi
Náš poster byl na Wikimánii
vyhlášen nejlepším obsahovým posterem. Autor: Emajeblahova,
CC BY 4.0, via Wikimedia
Commons
Klára Joklová se v Katovicích účastnila navíc řady partnerských
a pracovních jednání. Nadačnímu týmu Grow, který má mj. na starostí
partnerství a podporu poboček, např. prezentovala činnost CEE Hubu.
Na konferenci pak zastupovala postoje a potřeby české pobočky i CEE
regionu na strategických blocích o budoucnosti hnutí. S řadou
přítomných partnerů vyjednala také podporu realizace mezinárodní
konference pro mladé wikimediány v příštím roce v Praze. Žádost o
její podporu z konferenčního fondu WMF je nyní v procesu
hodnocení.
„Viacheslav Mamon z Ukrajiny, můj předřečník na Lightning
Talk Showcase, mluvil o tom, jak ukrajinští wikipedisté během
náletu na Charkov editovali Wikipedii v protileteckém krytu, aby
umožnili všem přístup k ověřeným a svobodným informacím. Tyto
konkrétní ukázky dobrovolnického odhodlání mají ohromnou sílu. Lidé
bojující za otevřenou a svobodnou kulturu jsou pro mě nekončícím
zdrojem inspirace. Díky Wikimánii se mohou jednotlivci napříč
hnutím setkat a vzájemně sdílet své příběhy a pohledy,“ říká
výkonná ředitelka WMČR Klára Joklová
Česká “delegace”
Wikimedia Česká republika letos poskytla aktivním členům české
Wikimedia komunity účastnická stipendia. Zaměstnance tak za spolek
doplnili grantisté Jan Myšák, V0lkanic, Blahma, cepice, LiMr a
Václav Zouzalík. Náš zaměstnanec Jan Beránek byl dokonce v
Katovicích v pozici člena jádra organizačního týmu a podílel se tak
na přípravě celé Wikimánie.
„Pestrost nabízených programů byla nekončící a společná
touha zlepšovat svět předáváním znalostí druhým byla téměř
hmatatelná. Až na pár výjimek jsem měl příležitost setkat se s
mnoha inspirativními lidmi nadšenými možností předávat své
zkušenosti dále. Setkal jsem se s wikipedisty různých kultur, a
dokonce jsem s překvapením objevil i zalíbení některých starších
wikipedistů v mobilních hrách. Každý den byl zajímavý něčím jiným a
přinesl vždy nadmíru přínosné informace a inspirace pro další
činnosti spojené s Wikipedií. Jsem zcela spokojen, že jsem mohl
navštívit svoji první Wikimánii,“ shrnul svou zkušenost
wikipedista Karel Čapka.
Mladí wikimediáni na Wikimánii
Více než polovina všech účastníků konference Wikimánie byla
mladší 35 let, což odráží generační změnu ve struktuře hnutí
Wikimedia. Proběhly zde také tematické meet-upy mládeže, které jsou
jedinečnou šancí pro členy komunity z různých zemí osobně se
setkat, sdílet nápady, informovat se o svých projektech či plánovat
nové spolupráce.
Výkonná ředitelka Klára Joklová je zakladatelkou neformální
skupiny mladých wikimediánů ze CEE regionu. Tato nyní silná skupina
CEE
Youth řadu těchto setkání iniciovala a vedla. Kromě
konferenčních příspěvků připravila mj. neformální herní večer pro
účastníky konference. Tam si s mladými zahrál i Jimbo – Jimmy
Wales.
Mladý wikimedián i člen spolku WMČR V0lcanic ke své účasti
říká:
„Letošní Wikimánie pro mě byla unikátní v několika ohledech.
Jednak díky své geografické blízkosti, jednak proto, že šlo o dosud
největší akci tohoto druhu, které jsem měl možnost se zúčastnit – a
to nejen v souvislosti s Wikipedií. Byly to tři dny nabité zážitky,
ať už šlo o přednášky, neformální konverzace, nebo jen o výborné
jídlo. Unikátní byla také příležitost vidět významné osobnosti
spojené s Wikipedií, např. jejího zakladateleJimmyho
Walese,, ředitelku Nadace WikimediaMaryanu
IskanderneboAnnie
Rauwerd z Depths of Wikipedia. Jsem nadšený, že jsme
se jako česká komunita mohli zúčastnit největší wikimediánské
konference vůbec.“
Jan Myšák, rovněž mladý wikimedián a člen spolku, jej
doplňuje:
„Program mě mile překvapil, opravdu málokdy mě nějaká
přednáška nezaujala, naopak jsem často chtěl být na dvou či třech
místech najednou. Ocenil jsem i možnost poslechnout si novinky od
vývojářů a dát jim zpětnou vazbu – tyto konkrétní prezentace a
meetupy byly podle mě možná to nejlepší z programu. Kromě spousty
nových tváří mi v paměti utkvěly případy nečekané (spolu)práce v
těžkých dobách a prostředích, jako jsou editace z ukrajinských
bunkrů nebo fungující program na Kypru. Také musím zmínit místo
konání konference – záměrně jsem si nestudoval, kam vlastně jedu, a
moderní centrum města mi doslova vyrazilo dech.“
Koncem května a celý červen se wikipedisté a wikipedistky
věnovali lidskoprávním a humanistickým tématům, historii a
osobnostem. Díky výzvě Lidská práva na Wikipedii,
kterou jsme letos pořádali již po třetí, se podařilo 33
wikipedistům a wikipedistkám vytvořit 99 článků a dalších
117 rozšířit – celkem jich editovali 216. Komunita
wikipedistů a wikipedistek se v rámci výzvy sešla dvakrát na živo:
na editatonu v centru Člověka v tísni v kavárně
Langhans a na exkurzi na Ďáblickém
hřbitově. Zároveň jsme uspořádali tři akce pro školy, na
ZŠ Londýnská, na Střední škole
informatiky, poštovnictví a finančnictví Brno a na
Dvořákově gymnáziu v Kralupech nad Vltavou. Celou
výzvu pak doplnil online workshop pro neziskové orgranizace.
Při pořádání výzvy jsme spojili síly s dalšími neziskovými
organizacemi, zejména Amnesty International, Nadací OSF a
Sdružením VIA. Akce proběhla pod záštitou zmocněnkyně
vlády pro lidská práva Kláry Šimáčkové
Laurenčíkové.
Cílem výzvy Lidská práva na Wikipedii je zajistit, aby měl každý
přístup k neutrálním a aktuálním informacím o lidských právech. K
takovým informacím, které jsou podloženy fakty a relevantními
zdroji. Výzvou upozorňujeme na fakt, že Wikipedie je často
primárním místem, kde veřejnost hledá odpovědi na otázky široce se
dotýkající lidských práv.
Společné editování Wikipedie v
Langhansu
Hlavní akcí výzvy Lidská práva na Wikipedii byl již tradičně
editaton v Kavárně Člověka v tísniLanghans ve spolupráci s Amnesty
International. Ve středu 26. června přišlo editovat
12 lidí osobně a 3 se připojili online.
Na editatonu jsme přivítali Martinu Wranovou z Amnesty
International. „Když jsem psala článek o redefinici
znásilnění, tak jsem byla překvapená, že ta editace článku je velmi
jednoduchá. Je to intuitivní a to je za mě super, protože to tím
pádem může dělat každý,“ říká. Na Wikipedii podle ní chybí
zejména témata, která nejsou mainstreamová: „Menšiny, ať už
náboženské, etnické nebo sexuální, nebo témata jako je sportwashing
nebo klimatická krize a dopady na lidská práva.“
Výkonná ředitelka Wikimedia ČR k výzvě dodala: „Už potřetí
jsme s výzvou oslovili desítky českých odborníků, kteří se věnují
širokému tématu lidských práv nejen v institucích, ale zejména
neziskových organizacích, které v Česku řeší nejrůznější
lidskoprávní témata. Většina organizací naši nabídku uvítala,
podpořila ji či přímo využila. Daří se tak doplňovat řadu
aktuálních témat a článků, které jsou často velmi
komplexní.“
„Lidská práva jsou strašně široká oblast, od konkrétních činů a
konkrétních lidí, až po složité zákony na mezinárodní úrovni.
Wikipedie může v tomto sehrát důležitou roli, protože může přinášet
jednodušším jazykem ty složité věci tak, aby jim každý z nás mohl
rozumět a dostal se k nim snadno online. Při prvním seznámení s
Wikipedií mě překvapilo, jak jednoduché je zapojit se a editovat
ji. V rámci editatonu jsem upravil stránku o ceně Gratias
Tibi.“
— Jakub Varvařovský, účastník editatonu a spoluzakladatel
Mnoho světů v Jilemnici
Lidská práva na Wikipedii
studentům
V rámci výzvy Lidská práva na Wikipedii jsme se věnovali také
studentům. Jednou z akcí byl workshop na druhém stupni
Základní školy Londýnskáv Praze,
kterého se zúčastnilo přes 50 žáků. Ti se tak dozvěděli, kdo
vytváří a kontroluje obsah na Wikipedii, jak Wikipedie funguje a
jestli se jedná o relevantní zdroj informací. Mimo to si sáhli
i na wikipedistickou praxi. Vyzkoušeli si totiž Wikipedii nejen z
pohledu uživatele, ale především editora. Na základě vybraných
článků o lidských právech se naučili, co a jak můžeme na Wikipedii
měnit a jakými pravidly je potřeba se při tom řídit.
Vedle toho proběhl na Střední škole informatiky,
poštovnictví a finančnictví v Brně již třetí ročník kurzu
pro studenty pod vedením pedagoga Martina Hájka, který vyvrcholil
17. června Editatonem lidských práv. A nově se
letos do práce na článcích o lidských právech zapojili také
studenti a studentky Dvořákova gymnázia v Kralupech nad
Vltavou, kteří absolvovali workshop Mediální
výchova a lidská práva na Wikipedii.
Ďáblický hřbitov jako místo paměti a
připomínka druhého a třetího odboje
V sobotu 15. června navštívilo s historikem, zaměstnancem
Vojenského historického ústavu a wikipedistou
Michalem Loučem 11 wikipedistů a wikipedistek
Ďáblický hřbitov – místo silně spojené s bojem za lidskou svobodu a
historií druhého a třetího odboje.
Dodržování lidských práv by mělo být samozřejmostí, ale jak je
známo z historie již od starověku, bohužel není. Ani v té naší
společnosti, která si říká „civilizovaná“. Boj za lidská práva je
trvalý proces, skončit nikdy nemůže a ani by neměl. Znovu jsem si
to uvědomila při nedávné Wikipedií organizované komentované
procházce po Ďáblickém hřbitově.
— Zorka Sojka, účastnice exkurze a
wikipedistka
Jak dostat vaše téma na Wikipedii?
Poradili jsme neziskovkám
Ve středu 5. června jsme uspořádali online workshop
„Jak dostat vaše téma na Wikipedii“ pro neziskové
organizace. Přestože byl workshop zaměřen především na
neziskové organizace, které se věnují tématům lidských práv,
složení účastníků bylo daleko pestřejší. Účastnili se ho jak místní
aktivisté a organizátoři lokálních akcí, tak zástupci neziskového
sektoru – např. Arnika – kteří
přišli s konkrétními náměty, jako je například chemické znečištění
krajiny. Záznam je k dispozici na YouTube.
Založené články: Lidská práva v
Polsku, Kulturní práva nebo Společnost pro queer paměť
Medaile a sleva na knihy pro všechny
zapojené, poukazy pro 10 vítězů
Všichni účastníci a účastnice výzvy získali virtuální
medaili – uživatelské vyznamenání vytvořené právě pro
tuto událost. Nadace Albatros zároveň ocenila všechny zúčastněné
30% slevou a dopravu zdarma na nákup v e-shopu
Albatrosmedia.cz.
Součástí výzvy byla i soutěž o poukázky do e-shopu
Albatrosmedia.cz pro 10 nejlepších, které opět do soutěže
věnovala Nadace Albatros. Tři poukázky získali
nejaktivnější přispěvatelé dle počtu založených nebo
významně rozšířených článků, dvě putovaly k zapojeným
nováčkům a dva uživatelé byli vylosováni
náhodně bez ohledu na počet napsaných článků.
Zbylé tři ceny udělili porotci Martin Strachoň a
Martina Wranová, jejich úkolem bylo ocenit editory a editorky,
jejihž příspěvky byly velmi kvalitní a týkající se lidských
práv – mohlo se tak jednat například o články významné z
hlediska těžkého zpracování, opomíjené osobnosti nebo další
důležitá lidskoprávní témata.
„Všimnul jsem si, že nám na české Wikipedii chybí většina článků
o lidech popravených v politických procesech po únorovém převratu.
Rozhodl jsem se, že se pokud možno o všech těchto obětech, o
kterých se dá něco najít, pokusím sepsat co možná nejvíc článků a
zanést jejich životní příběhy i na Wikipedii. Povedlo se!“
— V0lkanic, nejaktivnější wikipedista výzvy Lidská práva na
Wikipedii
Nejaktivnější
V0lkanic
89 příspěvků*
Karelkam
38 příspěvků
Meloun1212
9 příspěvků
Nováčkové
Adéla Baďurová
Honťák
Vylosovaní**
Ikcur
Ján Kepler
Cena poroty
Chavran97
tvorba kvalitních složených překladových článků o žurnalistce a
aktivistce Jeleně Kosťučenkové a
o ženském spolku Živena
Co by byla Wikipedie bez referencí a zdrojů? Jak by zachovávala
svou objektivitu? Byla by natolik důvěryhodným zdrojem? Odpovědi na
tyto otázky nejspíše všichni tušíme, ale naštěstí na ně ani
odpovídat nemusíme. Wikipedie naštěstí JE založena na
referencích a důvěryhodných zdrojích.
Čas od času se však i na Wikipedii objeví neocitovaná pasáž,
která nutně potřebuje kvalitní zdroj, je třeba ho tedy doplnit.
Pokud se považujete za wikipedistu opraváře či vám jen záleží na
kvalitních wikiheslech, existuje výzva přesně pro vás!
#1Lib1Ref probíhá ve všech zemích světa a má
motivovat (nejen) knihovníky, aby po vzoru encyklopedistů přispěli
alespoň jednou referencí k existujícím článkům.
Zapojit se může každý, ale proč právě cílit primárně na
knihovníky? Kdo jiný než knihovníci má takové předpoklady pro
udržování kvality citací na české Wikipedii? Knihovníci jsou
experti ve vyhledávání a poskytování informací a při své práci
dennodenně pracují s knihami a časopisy, které jsou pro Wikipedii
neocenitelnými prameny informací.
Připojíte se k wikipedistům z celého
světa!
Výzva #1Lib1Ref probíhá vždy dvakrát do roka (vždy v lednu a
květnu) po celém světě. V rámci výzvy taktéž běží soutěž, a to jak
v rámci České republiky, tak i celého středoevropského regionu.
Popasovat se tedy můžete nejen s tuzemskými wikipedisty, ale i
nespočty dalších!
Důležitá je pak spolupráce české pobočky Wikimedia jako takové.
Snažíme se
být mezi světovými komunitami vidět a nebojácně prezentovat
naše nápady. Mezinárodní komunita například ocenila
české wikivyznamenání za tuto
výzvu či videonávod přímo od
wikiknihovníků, jak se do výzvy může jednoduše zapojit každý
uživatel Wikipedie včetně úplných nováčků. Zároveň jsme
vyjednali, aby se mohli editoři zapojit do soutěže v rámci
středoevropského regionu, jak v rámci lednové, tak v rámci květnové
výzvy #1Lib1Ref.
Wikipedické vyznamenání,
které získali všichni účastníci květnového běhu výzvy.
Jak to letos dopadlo?
Do výzvy bylo možné se zapojit nejdříve od 15. ledna do 5.
února, poté od 15. května do 5. června. Editoři tedy měli celých 44
dní na to se do výzvy zapojit. Jak si vedli?
Na české Wikipedii bylo díky výzvě #1Lib1Ref podařilo
přidat či doplnit 310 referencí. Za tímto úspěchem
poté stojí 32 wikipedistů a wikipedistek. Z těch bylo oba dva
turnusy soutěže vylosováno 5 výherců, kteří svou prací získali
drobné ceny. Ve svých poštovních schránkách tak účastníci výzvy
mohli najít poukázky od vydavatelství Academia a KOSMAS, knihu či merch
spolku Wikimedia Česká republika.
Výherci letošních výzev se stali:
#1Lib1Ref leden 2024
#1Lib1Ref květen 2024
Aktron
V0lkanic
KKDAII
Linda.jansova
The Subterranean
PetrVod
Meloun1212
Dolečková Kateřina
Mojmir Churavy
Skot
Vítězům gratulujeme. Těšíme se opět za rok!
Jsme tu pro vás!
Součástí letošní výzvy 1Lib1Ref bylo mimo jiné školení
Přidej citaci na Wikipedii, které proběhlo v
pondělí 20. května 2024 a bylo zaměřeno primárně na knihovníky. Z
toho důvodu jsme přizvali ke spolupráci a propagaci Svaz knihovníků
a informačních pracovníků (SKIP). Díky této spolupráci bylo
doplněno více než 40 referencí a citací k existujícím článkům.
Účastníci se v rámci online školení od hlavního lektora Pavla
Bednaříka dozvěděli, proč a jak citace k článkům přidávat a jaká
jsou úskalí neozdrojovaných článků. Online záznam školení je k
dispozici na youtube kanálu Wikimedia ČR.
Součástí podpory v rámci výzvy 1Lib1Ref, ale i mimo období výzvy,
je pravidelná Wikiporadna, která nabízí konzultaci
každé pondělí od 18:00 hodin. Pro ty, kterým nevyhovuje pondělní
termín, je určena wikiporadna na objednávku – stačí si vybrat
z nabízených konzultantů i termínů.
Tak zas za rok, trošku jinak.
Na české Wikipedii probíhá výzva #1Lib1Ref již od roku 2022 a
každým rokem se do ní zapojuje více a více
editorů! V prvním turnusu této výzvy, tedy v lednu 2022,
se reference na Wikipedii rozhodlo přidat pouze dva uživatelé
Wikipedie se svými sedmi editacemi. Nepochybujeme o tom, že každá
reference má svůj význam a i za ně samozřejmě děkujeme. Na druhou
stranu nepochybujeme o tom, že na 310 referencí za rok se prostě a
jednoduše kouká lépe.
Jak jsme doplňovali
reference v průběhu let.
Pokud byste toto číslo však chtěli ještě vylepšit, šanci budete
mít příští rok, a to tradičně v datech 15. 1. až 5. 2. a 15. 5. až
5. 6.! Výzva #1Lib1Ref se vám dokonce představí i v novém
kabátku, a to s názvem „PŘIDEJ CITACI“, aby byla výzva
přístupnější a srozumitelnější tuzemskému uživateli. Těšíme se na
vás.
Letos měli fotografové díky Wikimedia ČR již podruhé příležitost
zapojit se do soutěže o nejkrásnější fotku české přírody Wiki Loves
Earth Czechia. Na výherních příčkách se umístili 3 fotografové. Do
mezinárodního kola soutěže postupuje deset fotografií.
Zvěčnění přírodních krás na Wikimedia
Commons
Druhý ročník českého kola soutěže
Wiki Loves Earth Czechia se konal od května do června. Jedná se
o soutěž, která se zaměřuje na dokumentaci
přírody v chráněných územích po celém světě. Národní kola
soutěže v jednotlivých zemích probíhajli až do konce července.
Nejlepší fotky z těchto národních kol se utkají v
mezinárodním finále. Soutěžící mají nejen možnost vyhrát a
postoupit, zároveň se podílejí na rozšiřování databáze svobodných
médií Wikimedia Commons, které mj. slouží jako ilustrace obsahu na
Wikipedii – a to celosvětově.
Nejlepší fotografie Wiki Loves Earth
Czechia 2024
V porotě soutěže usedl vítěz hlavní fotografické soutěže
Czech Wiki Photo Konstantin Zhdanov a vítězové
Mikrosoutěte Ohrožené stavby Anaj7 a Gampe. Na základě jejich
hodnocení byli vybráni tři vítězové a deset fotek, které postupují
do mezinároního kola soutěže.
Na prvním místě se umístil Luckhy86
hned se dvěma fotografiemi ptáků – Ledňáček na Lovu a Dudek
chocholatý při krmení mláďat.
Fotografové na prvních třech místech vyhrávají poukaz na
ročního předplatného programuZPS X na
úpravu fotografií od partnera soutěžeZoner a.s.
Patnáct postupujících
fotek
Patnáct nejlepších fotek, které postupují do mezinárodního kola
Wiki Loves Earth.
Foto: Stará Plynárna
Hřensko, Autor:
Michroucka, CC BY-SA 4.0, via Wikimedia Commons.Foto: Pyrrhocoris apterus,
Autor:
Wladislaw353, CC BY-SA 4.0, via Wikimedia Commons.Foto: Přehrada Seč, Autor:
Kylfas, CC BY-SA 4.0, via Wikimedia Commons.Foto: Pohled na CHKO České
středohoří, Autor:
Marek Šašek, CC BY-SA 4.0, via Wikimedia Commons.Foto: Po dešti ve
Středohoří, Autor:
Crutch1973, CC BY-SA 4.0, via Wikimedia Commons.Foto: Plechý, NP Šumava,
Autor:
Jiří Komárek, CC BY-SA 4.0, via Wikimedia Commons.Foto: Páření čápů bílých,
Autor:
Lubomír Dajč, CC BY-SA 4.0, via Wikimedia Commons.Foto: Pálavské zříceniny,
Autor: Kylfas, CC BY-SA 4.0, via Wikimedia Commons.Foto: Drátenická skála,
Autor:
Kylfas, CC BY-SA 4.0, via Wikimedia Commons.Foto: Dudek na příletut,
Autor:
Luckhy86, CC BY-SA 4.0, via Wikimedia Commons.Foto: Dudek chocholatý při
příletu s potravou, Autor:
Luckhy86, CC BY-SA 4.0, via Wikimedia Commons.Foto: Dudek chocholatý při
krmení mláďat, Autor:
Luckhy86, CC BY-SA 4.0, via Wikimedia Commons.Foto:Vážka žlutavá, Autor:
Lubomír Dajč, CC BY-SA 4.0, via Wikimedia Commons.Foto: Ledňáček na lovu,
Luckhy86, CC BY-SA 4.0, via Wikimedia Commons.Foto: Smolokorka
pryskyřičnatá s glutací, Lubomír
Dajč, CC BY-SA 4.0, via Wikimedia Commons.
Všem postupujícím gratulujeme a přejeme dobré umístění také na
mezinárodní úrovni.
Czech
Wiki Photo je hlavní fotografická soutěž
pořádaná spolkem Wikimedia
Česká republika. Je stálicí mezi fotografickými soutěžemi, ve
které se pravidelně utkávají stovky fotografů. Soutěž je
určena pro všechny amatérské i profesionální fotografy a fotografky
působící v Česku, kteří chtějí přispět k rozšíření obsahu
Wikipedie a dalších projektů Wikimedia svobodnými fotografiemi.
Cílem Czech Wiki Photo je motivovat fotografy k pořizování a
nahrávání fotografií, které mohou vhodně ilustrovat články na české
Wikipedii.
Soutěž probíhá každoročně v období mezi
1. listopadem a 31. říjnem následujícího roku.
Soutěžit lze ve třech hlavních kategoriích:
Příroda
Společnost, kultura a události
Vytvořeno člověkem
Protože je cílem soutěže získávat kvalitní fotografie, pro
ilustrace článků na Wikipedii je u fotografií vedle umělecké
hodnoty posuzována také její užitečnost.
Do každé kategorie může fotograf přihlásit až 3 fotografie.
Minimální požadovaná velikost souboru je 2 MB a nejmenší rozměr
kratší strany fotografie alespoň 2160 px. Fotografie musí být
pořízené na území České republiky.
Autoři nejlepších fotografií v každé kategorii soutěže Czech
Wiki Photo 2024 obdrží poukaz na roční předplatné programu
Zoner Photo Studio X od partnera soutěžeZoner,
wikipedistické vyznamenání a drobné ceny od spolku Wikimedia ČR.
Navíc bude oceněna i fotografie nejlepšího nováčka na
Wikipedii.
Jak se zapojit
Chcete-li se zapojit do soutěže Czech Wiki Photo 2024,
stačí nahrát své fotografie na Wikimedia Commons a vyplnit
správnou kategorii.Pro nahrávání fotografií je k
dispozicijednoduchý
formulář. Pokud nemáte zkušenosti
nahráváním obrázků na Wikipedii, na stránkách
soutěže naleznete stručný videonávod.
Soutěžní fotografie musí být pořízené na území České republiky v
období od 1. listopadu 2023 do 31. října 2024. Uzávěrka
soutěže je 31. října 2024.
Veškeré informace o soutěži včetně pravidel naleznete na
stránkách Czech
Wiki Photo 2024.
Encyklopedie Wikipedie v poslední době stále důrazněji dbá na to,
aby byly u článků a informací v nich uváděny správné zdroje. Je to
jen dobře, protože pouze touto cestou se může zvyšovat a podporovat
důvěryhodnost celého projektu.
Nicméně uvádění správných zdrojů by mělo být zásadou i pro jiné
profese, zejména pro novináře. Občas ale i žurnalista sklouzne na
šikmou plochu.
Humorný příklad přináší Lidové noviny ve svém článku "Pozor
na chřipku. Je tu epidemie" z 3. února. Autorka Silvie Králová
cituje řadu autorit a podle všeho ve většině případů seriózně.
Jeden zdroj ale budí úsměvné pochybnosti. Jde o tuto doplňující
pasáž:
„Chřipka začíná zpravidla vysokou
horečkou, okolo 38 až 40 °C,“ popisuje praktický lékař Jan Malý.
Vzestup teploty podle jeho slov obvykle provází zimnice a
třesavka.
Přidávají se silné bolesti hlavy. Ty mohou být spojeny i se
světloplachostí a ztuhlostí šíje. Časté jsou také bolesti kloubů,
svalů, očí, zad a nohou. To vše je spojeno s výraznou únavou.
„Dalším možným příznakem je nevolnost, někdy zvracení, průjem nebo
zácpa či nechutenství,“ říká doktor.
Během jednoho až dvou dnů nastupují již klasické příznaky z
postižení dýchacích cest. Je to rýma, bolest a pálení v hrdle,
suchý dráždivý kašel. Ten se postupem času zvlhčuje a mění v
hlenovitý kašel. Teploty, únava, bolest hlavy a svalů obvykle
vymizí během tří nebo čtyř dnů. Rýma a kašel pak trvají zhruba
týden až deset dnů.
Takže pan doktor Malý, no snad ne doc. MUDr. Malý CSc. z proslulého
IKEMu. Snad to bude nějaký jiný.
On totiž tenhle podivný doktor Malý doslovně cituje materiál, který
se objevil na webu Zdravotní pojišťovny Ministerstva vnitra už 7.
ledna. A těžko říct, jestli pochází zrovna odtud, protože se
nachází také na
webu Chřipka.cz. Dokonce Králová doslovně cituje i ty pasáže,
které se tváří už jen jako parafráze "doktorových" výpovědí...
Až budete psát svůj příspěvek do Wikipedie, nenechte se svést k
podobnému fabulování o zdrojích. Byla by to pro vás stejná
ostuda.
...proč je pro Wikipedii tak nebezpečné předpokládání zlé vůle.
V nejnovější sérii protestů na arbitráž, kterou sám vyvolal a která
se nevyvíjí podle jeho zadání, vytvořil Cinik obraz arbitrážního
výboru, který pracuje na základě nějakého jiného, cizího
zadání.
Jsem znechucen takovou argumentací. Nikdy jsem si nebyl zcela jist
tím, co dělám, a vždy jsem o svých krocích pochyboval. Nikdy jsem
si nebyl zcela jist tím, jestli odhaduji správně motivaci
ostatních, a když jsem začal mít pocit, že důkazy už téměř jasně
hovoří ve prospěch zlé vůle, znovu jsem si vše promýšlel a často
dospěl znovu k opačnému názoru.
Cinik ale odmítá připustit, že arbitrážní výbor má na věc zkrátka
jiný názor, a jednání arbitrů odsoudil nejostřejším způsobem včetně
obvinění z toho, že zcela záměrně rozhodují neobjektivně a
předpojatě.
Nebudu rozebírat Cinikovy námitky, protože mnohé zcela ignorují
zdůvodnění mých hlasů či hlasů mých kolegů arbitrů, některé to
zdůvodnění dokonce i popírají.
Nebudu zde vyvracet, že jsem neměl žádné zadání vysekat správce a
že pochybuji, že ho měli ostatní arbitři, a že jsem neměl žádné
zadání odsoudit Cinika. Neexistence něčeho se nedá dokázat a
důkazní břemeno leží na straně toho, kdo taková obvinění vynáší.
Místo důkazů pro taková tvrzení se ale často dočkáme jen osobních
dojmů, nezřídka podpořených tím, že domnělé fakty jsou "zjevné" či
že o nich "nikdo soudný nemůže pochybovat". Už jsem popsal svůj
pocit, který vzniká s nemožností obrany proti takovým
nactiutrhačným tvrzením: Znechucení. Proto pokud se dokážu obrnit
proti této nefér hře a nezanevřu svůj aktivní přístup k Wikipedii,
budu stále důrazněji usilovat o to, aby bylo vytváření obrazů zlé
vůle z Wikipedie vymýceno, protože je jedním z nejmocnějších
nástrojů k vytlačení těch, kteří zlou vůli ve skutečnosti
nemají.
Na závěr dodám, že Cinikovo vyjádření na blogu obsahuje několik
charakteristik, které jeho jednání arbitrážní výbor na základě
předložených důkazů již vyčítal, zmíněným předpokládáním zlé vůle
počínaje a osobními útoky, které tu nebudu opakovat, konče.
"Na rozdíl od Vás, já neměl o
výsledku arbitráže nikdy předem jasno - a nemám o něm jasno ani
teď. Připravují se rozhodnutí a já teprve zvažuji, jak o nich budu
hlasovat. Mohu Vás jen ujistit, že je o to těžší případ posuzovat
spravedlivě, pokud jedna ze stran zcela záměrně vytváří dojem, že
případ je již nespravedlivě rozhodnut. Pokud předem předpokládáte,
že Vám jako arbitr budu chtít škodit, jistě víte, které pravidlo na
Wikipedii se na to vztahuje."
Ne, tenhle text jsem nepsal dnes k Cinikovu ostře útočnému
vyjádření při odchodu tentokrát nikoli z Wikipedie, ale z
arbitráže. Tenhle text jsem
psal v červenci 2007 k předchozí arbitráži se Z. Tehdy jsem
skutečně nevěděl, jak se rozhodnu v hlasování, které začalo o více
než měsíc později. A bez veřejného povšimnutí adresáta jsem
skutečně později hlasoval u některých rozhodnutí zcela opačně, než
si dotyčný myslel.
Nyní už sotva několik hodin před hlasováním přece jen tuším (ale
pořád přesně nevím), jak se rozhodnu, ale jsem si téměř jist, že
Cinik to netuší a že pouze přistoupil k nátlakové operaci. Doufám,
že takový nátlak na mne nezapůsobí.
Je mi velmi líto, že se některé vzorce chování uživatelů, kteří
jsou stranami v arbitrážích, tak frapantně opakují.
Nikdy jsem netvrdil, že jsem právník, a tak používám jazyk
laickým, nikoli právnickým způsobem. Aby ale nepadla moje neznalost
neprávem na někoho jiného, tak zde opravuji chybný úsudek uvedený
na jednom blogu a zcela otevřeně se přiznávám k tomu, že autorem
spojení "pasivní práva" jsem já. Snažil jsem se odlišit práva "být
(chráněn, volen...)" a práva "činit" - tj. arbitrážní výbor přesto,
že wikipedistovi Z neumožnil na základě platného rozhodnutí činit
(účastnit se arbitráže), bude dohlížet na jeho práva, která
vycházejí z toho, že zkrátka je (potažmo byl) wikipedistou. Pokud
budou tato jeho práva nějak zkrácena, může se bezpochyby přiměřeným
způsobem obrátit i on sám na některého z pěti arbitrů. To
samozřejmě platí o libovolném wikipedistovi.
Také chci upřesnit formulaci, že výbor wikipedistovi Z zabránil
pomoct Vrbovi proti Cinikovi. Není to pravda a jednotliví arbitři
to ve zdůvodnění rozhodnutí jasně zdůraznili. Tuto pomoc může
poskytnout prostřednictvím například soukromé komunikace s kolegou
Vrbou, která v minulosti nebyla vyloučena - jak je tomu teď, nevím.
Tím ale také dostane příležitost konzultovat s ním, o jakou pomoc
stojí, samozřejmě - jestli vůbec Vrba o nějakou takovou pomoc
stojí. Pokud ale chtěl pomáhat jediným způsobem "na vlastní pěst" -
navíc způsobem, o kterém musel předpokládat, že je kvůli zákazu
jeho přispívání vyloučen, o jiné způsoby nestojí, pak chyba není na
straně arbitrážního výboru a já jako arbitr za to necítím sebemenší
zodpovědnost.
Pokud jde o zmíněnou další žádost, zcela neoficiálně oznamuji, že
ji výbor řeší, ale protože jde o citlivou záležitost, ve které jde
o osobní údaje, zatím hledá vhodný způsob. Určité prodlení je v
takové situaci nevyhnutelné.
Když jsem bilancoval 15 měsíců ve funkci arbitra, přešel jsem
možná až příliš stručně otázku jména wikipedisty Z. Ano, ve smyslu
příslušné
žádosti o komentář je skutečně nemožné vynucovat, aby se nikde
předchozí jméno wikipedisty Z neobjevilo. V tomto smyslu jsem to
koneckonců jasně formuloval též. Zároveň jsem ale jasně vyhlásil,
že prohřešky spojené s tímto jménem zůstávají prohřešky, ať jde o
osobní útoky nebo jiné nešvary.
Pro jistotu přesně cituji
vlastní slova: "Na druhou
stranu dodávám, že i vzhledem k této výzvě AC a vzhledem k tomu, že
nebyla (naštěstí) jednoznačně odmítnuta, považoval bych já osobně
nenásledování této výzvy za znak ne zrovna dobré vůle. To samotné k
blokování samozřejmě nestačí, ale může to pomoci v konkrétních
případech rozhodování, pokud jde o pochyby, zda jde o nějaké
jednání, za které se blokovat dá - tj. osobní útok
apod."
Částečný souhlas s Mercyho blokem
podal záhy další správce JAn. Myslím, že jeho vysvětlení bylo
velmi přesné, včetně výhrady k nesprávnému zdůvodnění. Otázka
přechylování jmen a konkrétně revertování tohoto jednoho doporučení
se Z nijak nedotýká, tudíž je zbytečnou provokací poukazovat na něj
jako na odstrašující příklad. Dle mého je to osobní útok a podle
předchozího vyjádření v ŽOKu takovému výkladu nahrává, že Cinik
navzdory doporučení arbcomu znovu záměrně použil původní jméno Z
(přičemž o něm dle mého psát neměl vůbec!).
Uvádím to jen proto, že část mého tvrzení byla nyní na Cinikově
blogu užita na jeho obranu. V tomto případě považuji blok za
správný a v přiměřené délce, jen jeho zdůvodnění bylo nepřesné.
Pokud nemůže kdokoli ovládnout puzení spojovat wikipedistu Z se
špatným, co se na Wikipedii děje, i když se to Z ve skutečnosti
nedotýká, je to o důvod víc, aby zásadně omezil užívání původního
jména Z. Jestli ale má před označením "wikipedista Z" osobní
zábrany, bude jen dobře, když mu budou bránit před podobnými
osobními útoky. Pevně věřím, že k takovému závěru dospěje po době
strávené při zablokování a podle následných reakcí i Cinik, jelikož
Wikipedii nijak neprospívá a prospívat nebude zcela zbytečné
oživování starých sporů.
Před několika dny jsem tu shrnul své zkušenosti z činnosti
arbitra za prvních devět měsíců funkčního období. I když zvlášť
jeden případ byl tehdy velmi složitý, mnohem inspirativnější
pro můj názor na práci arbitrážního výboru byly případy novější,
zvláště ten, který nám byl předložen v polovině května. Týkal se
sporu dvou zkušených wikipedistů Vrby a Luďka. Arbitrážní výbor
se tehdy
neshodl na tom, zda má žádost o arbitráž přijmout, nebo ne. Byl
jsem tehdy pro přijetí stejně jako che, Milda a timichal se
postavili proti. Výsledkem byl pat, který znamenal, že žádost
přijata nebyla.
Dodnes respektuji oba vyslovené názory, oba mají racionální základ,
opřený o zodpovědný výklad pravidel a zvyklostí na Wikipedii.
Protože považuji za důležité vyjasnit dostatečně můj obecný názor,
upozorňuji na přesné znění
příslušného pravidla: „Při
rozhodování, čím se zabývat, výbor přihlédne k názoru komunity a k
tomu, zda byly při řešení dotyčného případu vyčerpány jiné možnosti
řešení (přímá domluva mezi účastníky sporů, využití prostředníka
apod.).“ Rovněž tak z obecného úvodu: „Platí, že než se rozhodnete požádat o řešení
svého sporu arbitrážní výbor, měli byste vyčerpat všechny ostatní
možnosti.“ Formulace tedy podle mne dává najevo, že k
předchozímu řešení sporu se pouze přihlíží (tj. není to jednoznačné
rozhodující kritérium), není to povinnost, jen dobrá zvyklost
vyčerpat všechny ostatní možnosti. Žádost o komentář není nikde
výslovně uvedena vůbec. Pokud tedy toto pravidlo nebude
aktualizováno, budu nadále vyžadovat pro přijetí žádosti o arbitráž
předchozí ŽOK pouze v případě, že by mohla zásadně doplnit
proběhlou diskusi. Tato diskuse je naopak pro mne zcela nezbytná
(tj. budu vždy odmítat žádosti, které jsou podány ihned po vzniku
sporu bez jakéhokoli jiného pokusu o vyřešení), může ale mít různou
podobu. Doplňuji, že je to můj soukromý výklad uvedeného doporučení
a že – byť s výhradou – respektuji i výklad, který ŽOK
vyžaduje.
Přesto se domnívám, že arbitrážní výbor bohužel selhal v tom, že
nevynesl žádné společné stanovisko, kterým by žadateli jednoznačně
odpověděl. Je to pro mne dosud důležitá zkušenost, kterou jsem se
snažil v dalších dvou – o poznání jednodušších případech – řešit
poněkud nestandardním, ale podle mne přínosným způsobem „společných
stanovisek“ schvalovaných při (ne)přijímání žádosti.
Tato žádost bohužel také přinesla pro mne velmi znepokojivou
zkušenost dosud nejrazantnějšího pokusu o útok na jeho nezávislost
a akceschopnost, když wikipedista Nolanus
vznesl požadavek na převolení celého výboru v případě jednoho
konkrétního rozhodnutí. S takovým nátlakem na výbor
jako tehdy i dnes zcela zásadně nesouhlasím a odmítám se do
budoucna podřídit jakékoli podobné žádosti.
Netuším, zda se tento případ ještě někdy může k arbitráži vrátit,
ale přesto pro zájemce dodám, že jsem na základě tehdy předložených
indicií dospěl k názoru, že Luděk jako správce zásadním způsobem
nepochybil a nebyl bych tehdy ani nyní pro jeho pohnání k žádosti o
potvrzení správcem a byrokratem. Jsem si vědom, že Luděk udělal
množství nedobře působících kroků, podobně jsem to ale cítil i u
druhé strany a potažmo i u arbitrážního výboru.
Na tento případ navázala
žádost o komentář wikipedistky Vrbové, která na jednu stranu
zvolila poněkud zvláštní formu ŽOKu k arbitrážnímu výboru, na
kterou jsem
nenašel vhodný recept k chápání, navíc nevhodně zobecnila
některá fakta a použila je poněkud manipulativním způsobem (viz
hned první věta); na druhou stranu řekla různé věci, se kterými
souhlasím, a bylo to pro mne inspirativní. Podobné to bylo, když
Vrba s odstupem publikoval svůj názor na arbitrážní
výbor na svém blogu. Zvláště tato dvě vyjádření mne vedla k
zamyšlení a k tomu, že chci zkusit prosadit některé změny ve
fungování arbitrážního výboru a že chci působit sice v rámci
regulí, ale aktivně, nikoli pasivně, dokud budu arbitrem (tj. i v
případě, že budu usilovat o znovuzvolení).
V říjnu zaměstnal arbitrážní výbor
dvěma
případy wikipedista Hubený. Ani jednou výbor žádost nepřijal,
protože ani jednou nebyla podána jako dlouhodobý spor a nikdo ji k
takovému rozsahu nerozšířil. Za pozoruhodný moment a svým způsobem
za nedoceněný úspěch činnosti arbitrážního výboru považuji to, že
sám
žadatel byl spokojen s tím, jakým způsobem byla odmítnuta jeho
druhá žádost. Podle mne to bylo proto, že toto odmítnutí bylo
aktivní a pro všechny vyjádřilo jasné stanovisko výboru.
Nyní jen krátce k tomu, co bych rád na arbitrážním výboru změnil.
Myslím, že výbor se má na vyžádání hlavně dobrat k nějakému
rozhodnutí a to prezentovat. Aby ubylo co nejvíce momentů, kdy je
verdikt výboru nejednoznačný (týká se to především přijímání
žádosti), brzy předložím dva dílčí návrhy na změnu
pravidel arbitráže, potažmo
arbitrážního procesu. První se bude týkat toho, že arbitrážní
výbor by do budoucna neměl hlasovat o přijetí, ale o zamítnutí
žádosti (je to maličkost, ale při rovnosti hlasů má být
upřednostněno právo žadatele na to dostat odpověď než právo arbitrů
se té odpovědi vyhnout); druhá toho, aby celá fáze přijímání
žádosti byla upravena tak, aby i v ní měl povinnost arbitrážní
výbor odpovídat na zadané dotazy žadatelů a stran a aby bylo
zdůrazněno jeho právo i v této fázi vydávat svá stanoviska. Věřím,
že se pro takové úpravy podaří získat podporu.
Uplynulo již o něco málo víc než 15 měsíců od
zvolení stávajícího
arbitrážního výboru a přibližně do dvou měsíců už by měly být
vyhlášeny volby nové, jejichž hlasovací období by mělo nastat
krátce po Novém roce. Protože stále zvažuji, zda pokračovat v tomto
angažmá, rozhodl jsem se pro sebe i pro všechny ostatní udělat
shrnutí toho, co současný arbitrážní výbor řešil nebo třeba také
neřešil s mými soukromými poznámkami.
Samotné volby proběhly podle mého soudu poměrně kultivovaně a s
jednoznačným výsledkem, který rozdělil pole kandidátů na ty s
jasnou podporou a na ty bez ní. Značný počet hlasů pro byl pro mne
do značné míry závazek, a doufám, že aspoň u většiny hlasujících
jsem nezklamal a že z mého počínání mají aspoň takový pocit – tj.
převážné spokojenosti – jako mám já. Dodnes částečně lituji, že
nebyl zvolen
Mirek256, kterého jsem bez rozpaků podpořil i v hlasování. Na
druhou stranu nemůžu konkretizovat, místo koho by ve výboru musel
působit.
Krátce po volbách byl arbitrážní výbor postaven před těžký úkol
znovu projednat spory s wikipedistou Z. Připomínám, že od
zvolení výboru uplynuly v té době pouhé tři dny a že oba arbitři,
kteří měli z předchozí doby s touto funkcí nějaké zkušenosti, se
vyloučili pro podjatost. Přestože zbylá trojice, která hned v tomto
ostře sledovaném a kontroverzním případu musela hledat způsoby své
činnosti, byla občasně kritizována i za pomalost, byla žádost
projednána jen za necelé dva měsíce, a to většinou měsíce letních
prázdnin a dovolených.
Na základě vlastní úvodní aktivity s komunikací s wikipedistou Z
jsem byl později ostatními arbitry i formálně potvrzen jako první
zpravodaj výboru. Upřímně doznávám, že jsem tu roli nezastával rád,
protože šlo o krajně vyhrocený spor, v němž jedna strana
opakovaně zpochybňovala nezaujatost všech jednajících arbitrů,
odmítala plně spolupracovat a podobně. Nejsem se svým způsobem
koordinace činnosti arbitrážní výboru v tomto případě zcela
spokojen, hlavně ale ve mně zanechala celá záležitost jednu z
nejbolavějších zkušeností z „života“ na Wikipedii.
Nebyl jsem zcela spokojen ani s
výsledkem jednání výboru, v němž jsem byl přehlasován.
Myslel jsem, že pro tento způsob řešení by byla vhodnější
kratší než roční „zkušební doba“ než schválený rok. Alespoň se
podařilo prosadit – navzdory i
mé prvotní skepsi – návrh na
přejmenování arbitráže a omezení užívání původního jména
wikipedisty Z, který sice
není závazný, ale myslím, že posloužil k uklidnění na
Wikipedii. Vzhledem k nejistotě o výsledku rozhodnutí jsem dále
sledoval činnost wikipedisty Z na jiných projektech Wikipedie i na
jeho blogu a dospěl jsem k závěru, že verdikt byl přes mé původní
rozpaky správný. Dospěl jsem k názoru, že by Z těžko mohl být
součástí spolupracující komunity na české Wikipedii, což je na
druhou stranu škoda, protože jeho příspěvky jsou kvalitní, jak
dokazuje na jiných projektech. Bohužel se domnívám, že by přínos
jeho článků nevyvážil osobní spory plynoucí z dlouhodobé osobní
nevraživosti jeho a dlouhé řady jiných autorů české Wikipedie. Své
pochybnosti, které jsem měl o délce „zkušební lhůty“, se ukázaly
být irelevantní, protože o její délku Z nejspíš nikdy nešlo,
podstatnou byla podstata bloku do „žádosti o zrušení“, kterou
odmítá, ale s níž jsem i já souhlasil a souhlasím.
Pro plnou informovanost doplňuji, že krátce po arbitráži jsem byl
jako arbitr osloven wikipedistou Z, abych zprostředkoval jeho
kontakt se správci, což jsem
udělal. Wikipedista Z tehdy se mnou pokračoval v soukromé
e-mailové korespondenci, v níž jsme během několika dnů bohužel
dospěli k takovému vyostření sporu, že se nadále nepovažuji za
nepodjatého, pokud by arbitrážní výbor měl v budoucnu něco v
souvislosti s wikipedistou Z řešit a já byl jeho členem. Detailů
netřeba.
Už v té době byl arbitrážní výbor znovu požádán o aktivitu ve sporu
Medvídka Pú se správcem Horstem. Arbitrážní výbor se tehdy
jednomyslně rozhodl
žádost o zbavení správce jeho práv odmítnout. Medvídek Pú tehdy
neměl podporu nejen výboru, ale celé komunity pro své ostré
požadavky, nikde se nesnažil vyvolat diskusi, celý případ byl tehdy
proto jasný.
Jinak to ale bylo v případě
vrba versus Luděk, který spadl před arbitrážní výbor po půl
roce blažené nečinnosti. Přineslo to s sebou řadu dalších
záležitostí, takže to s dovolením vypíšu až příště.
Díky za zamyšlení, pokud vás moje zpověď k němu přivedla.
Dnes dopoledne jsem zase na Wikipedii vběhl trochu
nadšeně a nerozvážně, resp. hlasoval jsem ve správcovském
hlasování (správce však už drahnou dobu nejsem) za podporu bloku
Cinika na jeden měsíc. Zároveň jsem ale uvedl, že tento blok by měl
mít jisté podmínky, protože účel takovýchto akcí není nikoho
trestat, ale zajistit plynulé fungování encyklopedie jako
takové.
Proto by bylo dobré, kdyby Cinik ukázal, jaký je jeho záměr. Pokud
z Wikipedie skutečně definitivně odešel není potřebné, aby mohl
editovat - blok sice pozbývá významu, ale pro obě strany našeho
sporu. Tím pádem jsou jakékoliv stížnosti na měsíční blok naprosto
irelevantní.
Pokud však tohle ukončení aktivity bylo pouze krátkodobého
charakteru (jako tomu koneckonců bylo už dříve), bylo by dobré
ukázat také trochu přívětivější tvář. Ale nejprve ji musí ukázat
zablokovaný, který na svém
blogu šíří různé insinuační útoky na správce a vůbec
estabilishment Wikipedie. Tohle prostě nejde, to už se podobá... ,
je to fatální a musí to být odstraněno. Co Cinika v poslední době
trápí, o tom by bylo záhodno kdyby si správci s ním promluvili
(nejlépe nad kávou či pivem - tedy jedem dle chuti), někde v
příjemném prostředí. Přecijen tu máme uživatele, který pro
Wikipedii mnohé udělal (myšleno obsah) a jehož podíl není
oddiskutovatelný. Potom bude na místě, aby správci své drakonictví
odvolali a přistupovali mnohem vlídněji (koneckonců jedna z příruček Wikipedie nám povídá i o předpokládání
dobré vůle, ačkoliv mé očekávání, že k tomu skutečně dochází,
příliš valné není). Koneckonců, píše se jen encyklopedie,
nebudujeme stát.
Angličan
William
Webb Ellis (podstatně šířeji se o něm píše na anglické
Wikipedii, na fotografii jeho pomník ve městě Rugby) se zapsal do
historie světového sportu tím, že údajně vynalezl ragby. Jednou vzal při
školním fotbalovém utkání míč do ruky, proběhl hřiště a položil ho
do branky. Ragby je skvělý sport, ale fotbal byste si s takovýmhle
Ellisem nezahráli.
Vzpomněl jsem si na to při dvou víceméně úsměvných setkáních s
wikipedisty. Jeden se rozčílil, jak bylo naloženo s jeho
příspěvkem, který neodpovídal pravidlům, a hlasitě za sebou bouchl
na Wikipedii dveřmi. Připomínal mi právě ragbistu, který by chtěl
mermomocí prosazovat hru rukou v současném evropském fotbale a
kritizovat fotbalové činovníky, že mu neuznávají branky překopnuté
přes břevno. Inu, přeji mu hodně úspěchů v ragbyové kariéře, ale my
raději budeme hrát dál fotbal. :-)
I na druhé setkání se hodí příměr ze sportu. Že prý málo
profesionálů píše o svých tématech na Wikipedii a že je to ostuda.
Představme si turnaj mistrovství světa v malé kopané, na který
vyrazí nejlepší družstva třeba pražské hanspaulky (článek
o ní na Wikipedii stále chybí...). A jeden z těchhle kvalitních,
ale amatérských hráčů si povzdechne, že by se k nim měli přidat
nejlepší reprezentanti jako Tomáš
Rosický nebo Petr Čech a že je
škoda, že to neudělali, zvlášť když jsou za reprezentaci placeni.
Jasně, že ve skutečnosti je to trochu jinak, profesionálové obvykle
dělají svou profesi a na Wikipedii, která je koníčkem, už většinou
nemají čas. A pokud ano, raději tam napíšou článek o věcech, které
je jen baví.
Wikipedie žije vlastním životem, což je logické. Někdy mě ale
zaráží jeho sebestřednost. Někdy jí - na druhou stranu - propadám
sám.
Dlouhé čekání skončilo a Google spustil již na
začátku roku anoncovanýKnol. Je zatím ve zkušební beta
verzi, ale aspoň se můžeme konečně podívat, jak by to všechno
dosavadní tajemství mohlo vypadat a fungovat.
Na svém oficiálním blogu Google produkt představil. Jako hlavní
novinku uvádí metodu "moderované spolupráce. Každý uživatel může
navrhnout změnu či opravu textu, ale pouze jeho autor si sám
rozhodne, zda ji provede či ne. Autory mají být (a podle všeho
jsou) odborníci.
Co nyní Knol nabízí? Mnoho článků z oblasti medicíny, některé z
oblasti managementu, ale i kurioznější - i když pro někoho jistě
podstatné a užitečné - články
Ucpané záchody,
Grilovací omáčky nebo ze sportu
První ironman. Jako featured
knol (český překlad na takové spojení snad ani neexistuje,
něco jako článek v hlavní roli) nyní mají roztomilé
Jak si sbalit batoh (odborníkem na balení batohů je počítačový
inženýr z Kalifornie Ryan Moulton).
Ne, dost legrace, mám velké uznání ke všem, kteří píšou a tvoří (i
když to byl už snad Jan Werich, který řekl, že se teď víc píše než
čte...) pro druhé; a na tom nemění nic ani pocit, že bych raději
tyhle autory viděl přispívat na Wikipedii.
Někteří ale patří právě do kategorie profesionálních fotbalistů,
zmíněných v mém minulém článku, pro které Wikipedie není zcela
vhodným místem. Bude tedy na řadových wikipedistech, aby z jejich
tvorby na Knolu dokázali sami těžit. V současnosti jsou na Knolu
(namátkou) takové autority jako chirurg z Newyorské zdravotnické
školy Jessica Doningtonová, editorka Encyclopedia of Earth Ida
Kubiszewská z Vermontské univerzity, Robert Basner z Columbia
University.
Můj první dojem je celkem příznivý, což je jistě dáno i poměrně
hezkou úpravou (kategorizace asi časem dorazí a zatím ji nahrazuje
obstojné vyhledávání). Knolu ale tak trochu hrozí, že se změní v
"malý internet", ve kterém bude spousta článků nejrůzné úrovně,
jimiž se bude muset čtenář stejně probrat (aspoň budou snad
ohodnocené od ostatních). Uvidíme, jak se Knol vypořádá s články
typu
Mina Radhakrishnan, který by na Wikipedii právem zamířil ke
smazání z důvodů popsaných v doporučeních subpahýl,
WP:VL a
Propagační článek.
Celkový názor ale trvá, a tak ho můžu jednoduše
okopírovat ze svého půl roku starého příspěvku:
"Google Knol nikdy nebude
encyklopedie, bude to spíš sborník nebo rovnou knihovna, kam se
podíváte do poličky s knížkami o jednom tématu, kteří autoři tam
něco napsali. Z toho mi celkem jasně vyplývá, že nemůže být
konkurencí pro Wikipedii. Jen si Wikipedie musí uvědomit, že právě
onachce býtencyklopedií, že její hlavní
úlohou není vytvářet nové verze a nové interpretace informací, ale
jejich shromažďování a třídění. Wikipedie můžesnadno přežít Knol, stačí jen, aby se na
světě najednou zcela nevytratila kooperativnost a Wikipedii tak
naráz nevymřeli všichni přispěvatelé.
Přesto považuji případný vznik
Knolu za pozitivní. Shromážděný a aspoň po hromádkách článků na
stejné téma roztříděný bude zajímavým zdrojem informací - ve svém
utřídění lepší než obyčejné blogy, kterým se částečně podobá;
nikoli konkurenčním, ale alternativním vedle Wikipedie."
Dodám jen to, že větší konkurenci by mohl Knol představovat pro
některé jiné projekty Wikimedia, zvláště pro Wikiverzitu,
kde by se ale měly bezpečně udržet především kolektivní
projekty.
Poslední dobou se někteří wikipedisté baví vskutku zajímavým
způsobem. A to otázkou, kolik (a jakých) obrázků bude v článku o
severočeské obci Rybniště (zvláštní, vždycky jsem si myslel, že se
jedná o Jižní Čechy, ale budiž).
Autorem velkého množství obrázků z dané lokality je ŠJů, v současné
době nejaktivnější fotograf české Wikipedie, byť kvalita jeho
snímků je samozřejmě diskutabilní (a také se o tom živě a žhavě
mluví - i já sám ho na to už celkem nevybíravě
upozorňoval). ŠJů věnuje mnoho svého úsilí k zmapování mnoha
obcí, které dosud na Wikipedii nijak obrazově ztvárněny nejsou.
Místo pádné diskuze, kde by byly použity argumenty však člověk vidí
neustálé bazírování na detailech (extrémní konkretizace obecného mi
ale příjde poslední dobou jako velký problém na Wikipedii), jako je
třeba nepříliš šťastné umístění obrázku s valníkem hnoje do článku
o obci, že fotka návsi obce neříká vlastně o obci nic, v neposlední
řadě zakládání Žádosti o komentář a všeobecně a vůbec celkem
neslušný tón, který uživatele donutil vzít si na několik dní
timeout.
Každopádně mě překvapilo, jak rozsáhlý a dlouhý text jsou schopní
všichni velmi rychle v tomto ŽOKu vyprodukovat. Ještě více se divím
faktu, že někteří nejsou schopni tolerovat více obrázků v nějakém
článku, avšak faktické přehmaty v článcích, mnohdy až čtyři roky
staré údaje (normálně by to nevadilo, ale tohle je Wikipedie),
různé spamy a další nesmysly, nikomu nevadí. Alespoň tedy ne do té
míry, aby se to řešilo obdobnou cestou, jako jsou fotky
Rybniště.
Musím na druhou stranu přiznat, že k ŠJůovi jsem měl také nemalé
antipatie, zvlášť tedy v době, kdy jsem přeorganizovával všechny
články o dopravě a moje koncepce se střetla s jeho :-) Tyto
technokratické úvahy mě však naštěstí již opustily, neboť je
důležité si uvědomit, že dělat má ten, kdo dělat chce a bránit mu
je prostě kontraproduktivní. Normy, které Wikipedie nepřímo
vyžaduje, jsou podle mě dost volné na to, aby umožnily tvůrčí
schopnost všem. Že se to bude lišit, to je nutné přijmout jako
nutné zlo a danou pravdu. Lidé jsou různí, myslí různě a píšou
různě. Pokud tam nebude 40 obrázků k jednomu odstavci nebo celý
text růžovou kurzívou tak to žádná katastrofa není.
Na serveru Lupa napsal Michal
Černý článek Online
encyklopedie nejsou jen Wikipedie. Článek má standardní slušnou
kvalitu, snad jen určení toho, co odlišuje online encyklopedii od
všeho internetu, se myslím trochu minul se skutečností - hlavní
výhodou každé encyklopedie proti "pouhému" výsledku vyhledávání
tématu na internetu podle mého je, že má (a často to dělá - to je
právě chyba ne/populárních wikipedických pahýly) obsahovat pokud
možno souhrnnou informaci, kterou uživatel na internetu musí
kompilovat sám z více zdrojů.
Článek doprovází anketa "V jaké jazykové mutaci dáváte přednost
Wikipedii?" Výsledky jsou pro českou Wikipedii velmi příznivé. V
době psaní tohoto příspěvku jí dávalo přednost 54 % čtenářů článku
na Lupě. 39 % upřednostňovalo anglickou Wikipedii, každý padesátý
jiné jazyky a tři ze sta jiné online encyklopediíe. Je
pravděpodobné, že podhodnocena je skupina "Encyklopedie online
nevyužívám vůbec" (1 %), kterou takový článek asi ani nepřitáhl, a
proto její příslušníci nemohli hlasovat, výsledky u prvních čtyř
odpovědí by ale podle mne měly být zatíženy jen statistickou chybou
způsobenou malým počtem hlasujících.
V současnosti zaujímá Wikipedie dominantní místo mezi
encyklopediemi, boj o čtenáře se však přesouvá jinam. Jak oznámil
čtvrteční El País, tento týden začala digitalizace starých děl z
knihoven Universidad de Complutense de Madrid a Biblioteca de
Cataluña ve Španělsku.
Kdo za vším stojí? Jedná se o světový internetový gigant Google. V
plánu je zdigitalizovat většinu starších děl dostupných jako volná
díla. Celkem se má jednat o více než 700 děl, mezi nimiž se dá
nalézt například Cervantesův Důmyslný rytíř Don Quijote de La
Mancha, Kosmografie od Claudia Ptolemaia či Knihy o astronomii od
Alfonse X. Moudrého. Ostatní díla s copyrightem pak budou nabízena
ke koupi, nebo odkazována do "kamenných" knihoven.
Boj na poli encyklopedií postupně vyhrává Wikipedie. Již v roce
2005 si nechal renomovaný časopis Nature vyhotovit studii
porovnávající kvalitu světoznámé encyklopedie Britannica a
Wikipedie. Studie ukázala překvapivý výsledek a sice, že Wikipedie
si na tom nestojí tak špatně jak se původně předpokládalo.
Počátkem dnešního roku pak řada "tradičních" encyklopedií oznamuje,
že přechází k zpřístupňování hesel přes internet. Naproti tomu
německá Wikipedie připravuje vydání dalšího DVD a dokonce má v
plánu vydat i tištěnou verzi Wikipedie.
Postupně od dosažení 1,6 milionu hesel na anglické Wikipedii se
stále více a více volá po kvalitě. Postupně s nárůstem hesel se
hesla rozepisují, prohlubují; důležité a sporné údaje jsou
odzdrojovány, čtenářům jsou nabízeny sekundární zdroje typu
externích odkazů či literaturu. Některé vzdělávací instituce se
organizovaně vrhají na Wikipedii a zkvalitňují hesla. Díky softwaru
MediaWiki má každý možnost opravit chybu, kterou právě nalezl a v
mžiku nabídnout opravenou verzi milionům lidí po celém světě, kteří
mají přístup k internetu.
I Google se pokouší vytvořit vlastní "encyklopedii", v současnosti
však, zdá se sází více na jiné cesty, jak přilákat čtenáře. Stává
se výraznou konkurencí pro Wikisource. Digitalizace starých děl pro
potřeby Googlu už běží v několika zemích v různých světových
jazycích. Otázka je kdy se dostane i k nám? Jak někde uvedl Jimmy
Wales: pokud vývoj Wikipedie trvá 5-8 let, vývoj Wikiknih může
trvat 30-40 let. A podobné by to mohlo být s projektem Wikisource.
Nejde totiž to to, že by díla nebyla dostupná, ale spíš o
nedostatek ochotných editorů, kteří by se takovéto práci s chutí
oddali. Svou roli zde hraje i přizpůsobení softwaru tomuto
projektu.
Je tedy otázkou, jestli má cenu do budoucna s takovýmito projekty
soupeřit, pokud jsou cíle stejné? Nabídnout volně přístupná díla v
digitalizované podobě na internetu. Je nutné na tomto poli s někým
soupeřit? Faktem však zůstává, že v současné době se na českém
internetu nachází, hned několik internetových knihoven. Jsou lepší,
horší a dokonce narazíte i na úplně katastrofální projekty (u
takových se pak člověk podiví, na co všechno je možno dostat
grant). Žádná z těchto knihoven však zatím nepřistupuje k
digitalizaci tak široce, jako Wikisource.
Zdroj: El País, 3. července 2008, č. 11 442, evropské vydání.
Německý
wikipedista čínského původu Tching Čeng (známý nejčastěji s
přezdívkou Wing), byl zvolen
zástupcem komunity v Radě nadace Wikimedia Foundation. Ve složitém
systému, ve kterém se porovnával každý kandidát s každým, byl
upřednostněn
proti všem oponentům.
Wing se narodil v Šanghaji, vyrůstal v Cha-er-pinu a od svých 20
let žije v Německu. Nyní působí v Mohuči jako programátor u IBM.
Edituje čínskou, německou a anglickou Wikipedii. Spolupořádal
Wikimanii 2007 na Tchaj-wanu.
Zde je pět programových bodů, se kterými do Rady
kandidoval:
Podpora rozvoje softwaru MediaWiki pro lepší uživatelnost;
Podpora kroků k získání a udržení nových editorů;
Zajištění komunikace mezi komunitami Wikimedie, ať jde o různé
projekty, nebo různá místa;
Podpora jazykové, kulturní a dalších různorodostí komunity
Wikimedia;
Podpora spolupráce mezi Wikimedií a univerzitami nebo jinými
neziskovými/veřejnými institucemi zabývajícími se výzkumem a
vzděláním (např. knihovnami).
Na prvních nezvolených místech zůstali Australan ruského původu
Alex Bakharev a Američan Samuel Klein. Všichni kandidáti byli
označení hlasující komunitou jako lepší než Američan Gregory Kohs,
který svou kandidaturu formuloval dle mého názoru nejkritičtěji
(podobně neúspěšná byla rovněž hodně kritická kandidatura jeho
krajana Kurta M. Webera). Jen o jedno místo výš skončil Angličan
Paul Williams, nad jehož nízkým věkem (18 let) jsem se pozastavoval
zde na blogu i já.
V Radě jsou kromě Tchinga její předsedkyně Florence
Nibartová-Devouardová, stálý člen Rady a zakladatel Wikipedie Jimmy
Wales, dále místopředseda Jan-Bart de Vreede, Kat Walshová, Frieda
Brioschiová, Michael Snow, tajemník Domas Mitsuzas a pokladník
Stuart West.
Zdroj fotografie: Wikimedia
Commons (autor Wing
- mimochodem, přijde vám to jako autoportrét???)
13.
června 2008 zemřel americký televizní publicista, dlouholetý
moderátor pořadu stanice NBC Meet the PressTim Russert. Není mi
nijak známo, že by za svého života významně zasáhl do běhu
Wikipedie. O to víc na ni může zapůsobit paradoxně po své
smrti.
Russet zemřel po záchvatu, který ho postihl ve 13:30 přímo v
kanceláři. Televizní stanice informaci zveřejnila až po informování
jeho rodiny. Na Wikipedii se informace o jeho smrti objevila 13.
června v
20:01, ale
o devět minut později byla ze stejné IP adresy znovu
odstraněna, což bylo vzápětí revertováno. Ve
20:29 už byla informace podložena zdrojem z New York Times a od
té doby ponechána (aspoň předpokládám, protože jsem tu přibližně
tisícovku(!!) editací provedených v následujících necelých dvou
týdnech už dál převážně neprocházel).
Nenápadná záležitost, dohledatelná z historie článku, má ale
důležité konsekvence, o kterých se (pokud jsem znovu něco v
historii nepřehlédl) v článku na Wikipedii nepíše.
Údaj se totiž do Wikipedie dostal před oficiálním zveřejněním,
sotva několik minut po jeho úmrtí. NBC byla šokovaná a začala
vyšetřování, které ukázalo, že anonymním editorem je zaměstnanec
servisní společnosti NBC, která nese název IBS. Ve stejné firmě
pracoval i editor, který informaci zase odstranil, z časových
konsekvencí internetoví komentátoři usuzují, že na základě
stížnosti NBC, což podle mne není tak úplně jasné.
Podle dostupných informací se ale bezmála zdá (a komentátoři se na
tom shodují), že ten první zaměstnanec ani nevěděl, že dělá něco
špatného, protože předpokládal, že dává na internet veřejnou
informaci. Přesto byl propuštěn, možná jen proto, aby si IBS
zachovala tvář před NBC a tím i její přízeň. Šlo totiž spíš (jak
píše třeba Liz Wolgemuthová z US News) hlavně o věc
loajality.
O události informují například britský
Telegraph. V New York Times se Noam Cohen
pozastavuje nad tím, že NBC záměrně zadržovala informaci, než
ji zveřejnila.
Wikipedie se (viz NYT) stala v této události důležitým zdrojem
informací ve chvíli, kdy mnoho novinářů mělo zprávu o Russertově
nevolnosti, ale nikoli o jeho aktuálním stavu.
Mathew Ingram z torontského Globe and Mail se na vlastním blogu
ptá: "Byl čin osoby, která
změnila stránku na Wikipedii, žurnalistikou, nebo vyzrazením
privilegované informace? Podle mne to druhé, ale společnost chce
jasně udržet NBC jako svého klienta." ("Was the person who changed the Wikipedia page
committingan act of journalism, or divulging privileged
information? I’d vote for the latter, but clearly the company wants
to keep NBC as a client.") A publicista Mike Masnick
mu na Techdirt odpovídá:
"To bývala mnohem jednodušší
otázka, když novináři byli novináři a privilegované informace byly
privilegované informace. Ale hranice obou věcí se poměrně
rozmazaly, a tak to povede jen k dalším otázkám, než se společnost
dohodne na odpovědi." ("This used to
be a much simpler question when journalists were journalists -- and
privileged information was privileged information. But the
boundaries of both things have become quite blurred these days, and
that's only going to result in more questions being raised before
society agrees on the answers.")
Na jednu stranu by to pro Wikipedii mohla být pozoruhodné
informační vítězství nad ostatními médii (čistě formální připomínka
zní, že ještě lépe se to mělo objevit na Wikinews, které jsou
určené pro zprávy, na Wikipedii by se taková informace měla přece
jen objevit až jako podložený údaj), pokud by mělo být takové
usilování o rychlost jejím cílem - o čemž nejsem přesvědčen.
Mimochodem - o tom píše i autor Noam Cohen v New York Times
("V případě Wikipedie je to právě
to, k čemu site nemá sloužit. Jedním z principů situ je Žádný
vlastní výzkum - každý fakt se musí objevit v nějakém zdroji s
reputací, než je ho možné zopakovat." ("In the case of Wikipedia, this is emphatically
not what the site was meant to do. One of the principles of the
site is No Original Research — every fact must have appeared
somewhere reputable before it can be repeated.")
Na druhou stranu taková událost ukazuje, že editování Wikipedie
může být i záležitostí svým způsobem nebezpečnou...
Zdroj fotografie: Flickr - via
Wikimedia Commons (autorhyku)
Jako Ženevský
zázrak pojmenoval autor Reisender svůj
článek, který věnovat vyřazení českých fotbalistů z
mistrovství Evropy ve fotbale. Článek neobsahuje nic
závratného, není ani nijak ozdrojován a navíc kvůli probíhajícímu
hlasování o smazání bude pravděpodobně brzy smazán (proto
přikládám pro pozdější čtenáře odkaz na
kopii ve vlastním uživatelském prostoru na cs.wiki).
Je to ale - co jsem si všiml - jeden z nemnoha případů, kdy se
česká reálie stala hlavním tématem článku na en.wiki v okamžité
reakci na událost, a aniž by její vytvoření inicioval český editor.
Reisender se k tématu
podle všeho dostal spíš jako Chorvat, který s překvapením
zjistil, že soupeřem jeho týmu ve čtvrtinále nebudou očekávaní
Češi, ale Chorvati.
Smazání na anglické Wikipedii dovedu pochopit (zvlášť v současném
stavu článku), ale na druhou stranu zvláště na české Wikipedii by
takový článek být mohl, a to podle mého názoru na to, že česká
Wikipedie má zvláště zdůrazňovat
český rozměr zobrazovaných materiálů.
Doplnění: Článek byl
skutečně
smazán 23. června. Těsně před tím proběhl i pokus o jeho
přejmenování na Krále
comebacků. Výsledek diskuse nakonec byl mnohem těsnější, než
to zpočátku vypadalo. Na české Wikipedii by podle mne vedl k tomu,
že by článek zůstal ponechán. Při pouhém sčítání hlasů mi vyšel
výsledek 21 pro smazání, 16 pro ponechání, možná jsem se
přepočítal, ale těžko tolik, aby to přeskočilo hranici 2/3.
Protože
Wikiverzita i Wikizprávy už byly schváleny, je třeba se připravit
na ostrý provoz a udělat taky něco proto, abychom nekoukali jako
kedlubny, až doménu dostaneme. Zatímco pro Wikizprávy se logo
udělalo už před časem a na hlavní straně je (a já možná ještě
udělám nějaký alternativní verze pro milníky, 200 článků se nám
pomalu pozvolna blíží), Wikiverzita neměla vůbec nic. A tak jsem se
na popud Dannyho B rozhodl logo udělat.
Nebylo to nic složitého, stačí vzít jakékoliv logo, které už
existuje a doplnit pouze lokalizovaný text (narozdíl od Wikipedie
či Wikislovníku k tomu tak není potřeba přidávat ještě nějaké menší
texty pod názvem projektu, to zde odpadá. A ono je to i lepší;
pořádné informace jsou na příslušných stránkách, z hlavní odkazané,
není problém se k nim doklikat. A editorům log se hlavně usnadní
práce :-)
Už jsem tu jednou velmi okrajově zmínil, že se chystají volby do
správní rady Wikimedia Foundation - tedy do té části, o které
rozhodují členové komunity. V tuto chvíli se přijímají kandidatury,
uzávěrka má být zítra.
Zaujaly mne regule, podle kterých je možné volit nebo být
volen.
Volit může ten, kdo měl aspoň 600 editací před 1. březnem 2008 na
jedné nějaké wiki, 50 editací na té samé wiki od 1. ledna do 29.
května 2008, není zablokován a není bot.
Kandidovat může ten, kdo měl 600 editací na nějaké wiki před 1.
lednem 2008, má 50 editací mezi 1. lednem a 1. červnem 2008, je mu
aspoň 18 a je plnoletý ve své zemi a zveřejnění své občanské jméno.
Zajímavé pro mne je, že v zásadě není moc velký rozdíl mezi
požadavky na počet editací.
Co mne také zaujalo, je velmi nízký průměrný věk
přihlášených kandidátů. V době, když jsem psal tenhle článek,
jich bylo 11 a ten věk byl 32 let (a myslím, že ho zvedly poslední
přírůstky do seznamu). Do rady kandidují i zájemci ve věku 18
(Paul
Williams - na fotografii), 22, 23 a 25 let. Že uživatel ve věku
18 let bude schopný vykonávat povinnosti v radě v plném požadovaném
rozsahu, prostě nepředpokládám, ale každý volič si udělá názor
sám.
Jinak jsou v seznamu kandidátů čtyři Američané (a k nim jeden
Kanaďan, dohromady průměrný věk 27 let), čtyři kandidáti z Evropy
(průměr 36 - a to ho snižuje Williams), jeden Izraelec a jeden
Australan.
Volby proběhnou od 1. do 21. června 2008.
Zdroj obrázku: Flickr via
Wikimedia Commons (autor Peter)
I když jsem měl určité pochybnosti o jednom z projektů, iniciátorům
i dosavadním přispěvatelům oběma upřímně gratuluju, protože odvedli
dobrou práci. V zastoupení všem ostatním gratuluji těm
nejaktivnějším - u Wikizpráv jde
především o Aktrona,
Orange.mana,
Dannyho
B. a Darkermonka.
U Wikiverzity
jasně nejvíc práce odvedl Juan a s ním
Kychot.
Přeji všem po spuštění hodně spokojenosti z příspěvků publikovaných
v přátelské a tvůrčí atmosféře.
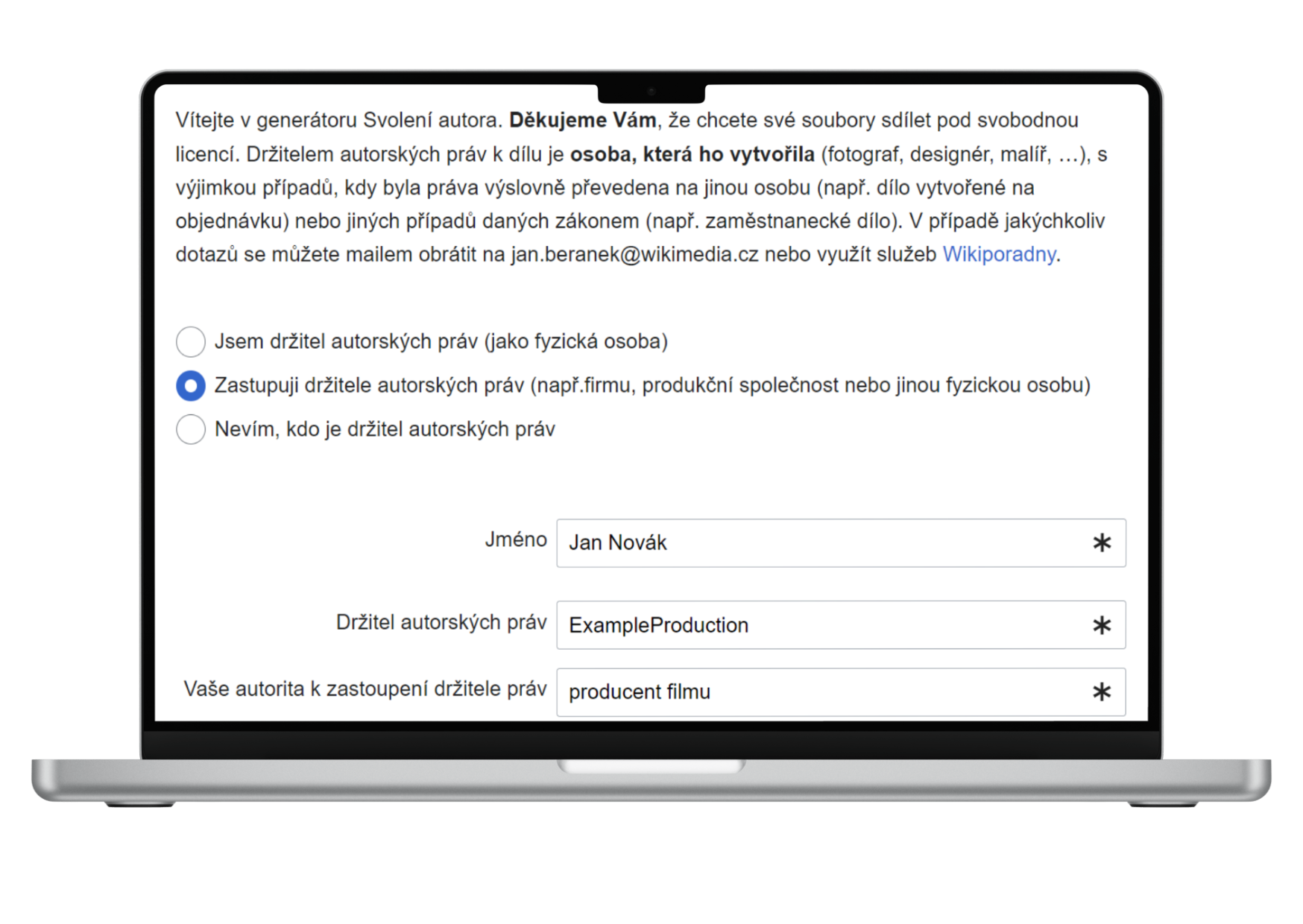





















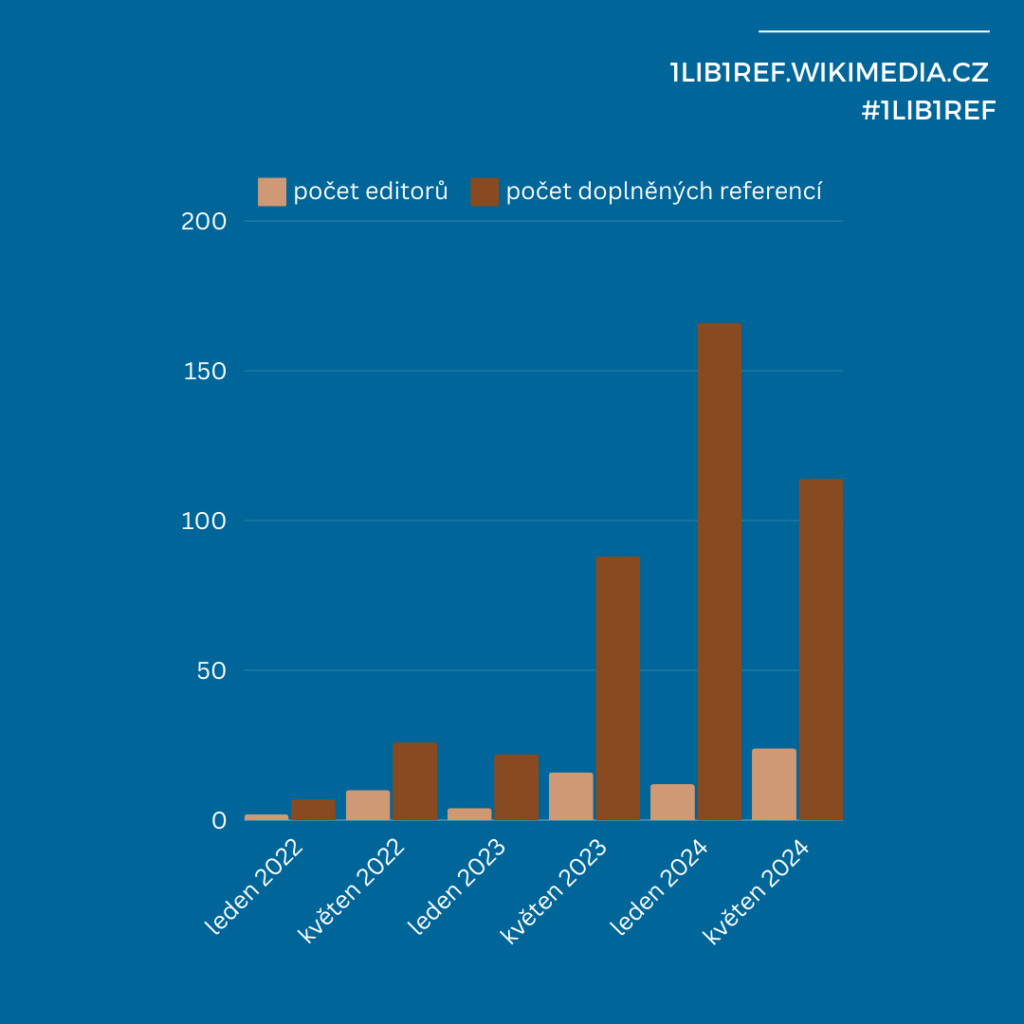






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}